Tacotron 2
October 25, 2020
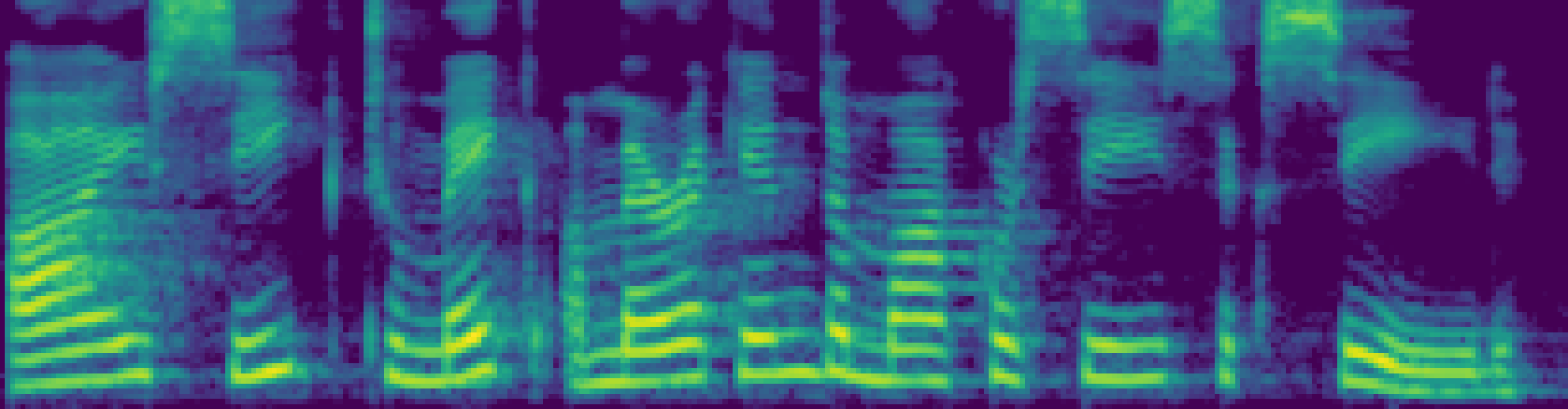
Text source: The Fireside Chats of Franklin D. Roosevelt. Audio source: LJSpeech-1.1/LJ024-0142.
Tacotron 2 is a Text-to-speech (TTS) model developed by Google. It consists of two components, a recurrent sequence-to-sequence architecture with attention that generates a magnitude mel-spectrogram from a sequence of characters, and a modified WaveNet which generates audio (time-domain waveform) from the mel spectrogram. The second component is called a vocoder. In this post, we will only look at the training of the first network to generate the mel spectrograms. We will use the Griffin-Lim implementation in librosa to obtain the audio from the mel spectrograms.
A single training iteration (forward and backward propagation) invokes about 12,000 GPU CUDA kernels for every second of audio! Fortunately, there is a lot of repetition, due to the architecture being recurrent. The best way to understand a DL network and GPU performance is to understand every single CUDA kernel i.e. which layer of the network invoked the kernel, with what arguments (tensor shapes and datatypes) and in which direction (forward or backward).
In this post, we will categorize every kernel used in the training
of Tacotron 2. All the information in the tables below was obtaining
using Nvidia's PyTorch Profiler, PyProf, on a Turing T4 GPU. The
information below is only a subset of what is provided by PyProf.
The code for Tacotron 2 was obtained from here. The annotated code
and instructions for obtaining a detailed profile are here. Note
that different GPUs will have slightly different kernel names e.g.
volta_* as opposed to turing_*.
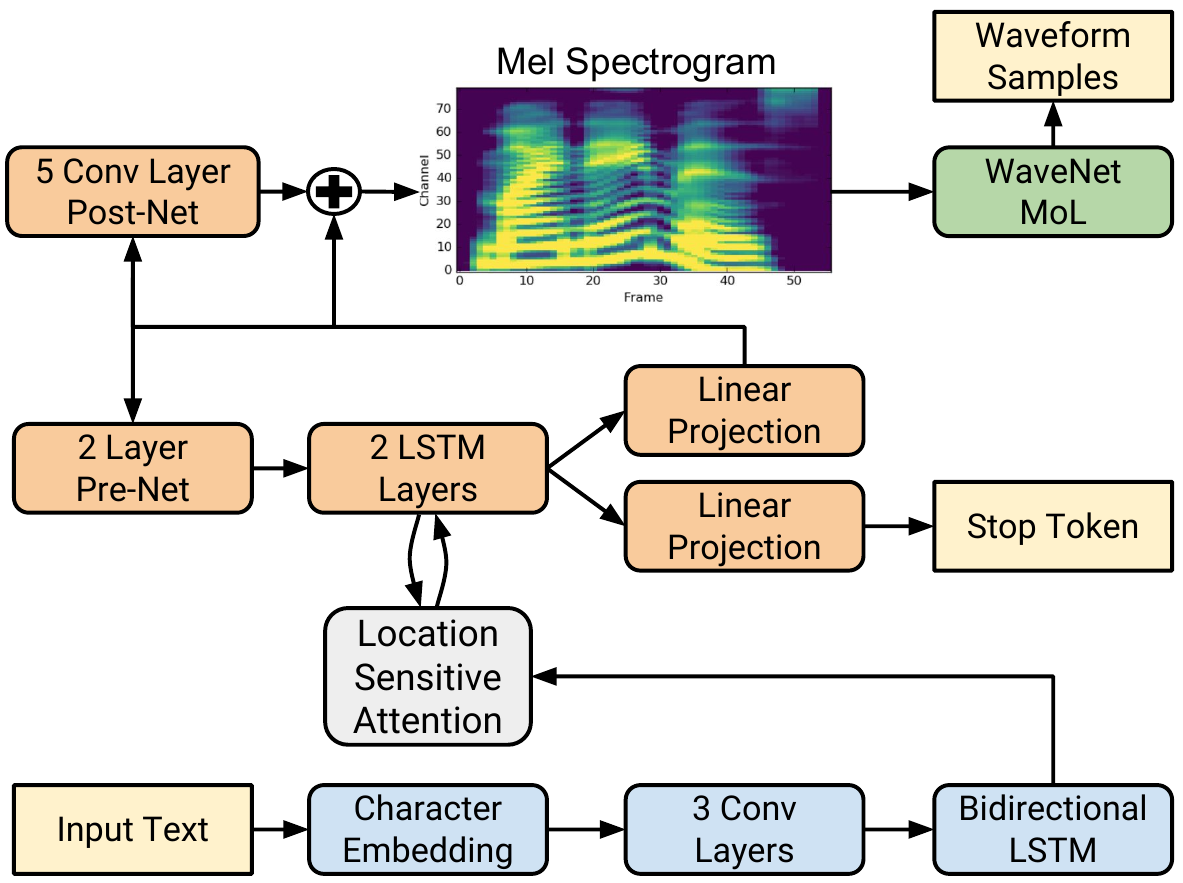
Model Architecture
For profiling, we used a single short sentence "In his defense"
(LJ011-0028 from LJ Speech Dataset) repeated 64 (batch_size)
times. The length of the corresponding audio is about 1 second. The table
below shows the output mel spectrogram and the corresponding audio
(obtained using Griffin-Lim) at various points during the training. The
parameters in the code are here.
| Label | Mel Spectrogram | Audio using Griffin-Lim |
|---|---|---|
| Epoch 0 |  |
|
| Epoch 100 |  |
|
| Epoch 200 |  |
|
| Epoch 300 |  |
|
| Epoch 400 |  |
|
| Epoch 500 |  |
|
| Target |  |
Model Parameters
batch_size = 64
# Character Embedding
n_symbols = 148
symbols_embedding_dim = 512
# Encoder Convolution
encoder_kernel_size = 5
encoder_n_convolutions = 3
encoder_embedding_dim = 512
# Audio Parameters
sampling_rate = 22050
filter_length = 1024
hop_length = 256
win_length = 1024
n_mel_channels = 80
mel_fmin = 0.0
mel_fmax = 8000.0
# Decoder PostNet
postnet_embedding_dim = 512
postnet_kernel_size = 5
postnet_n_convolutions = 5
# Location Layer parameters
attention_location_n_filters = 32
attention_location_kernel_size = 31GPU Kernels
The tables below show the GPU kernels invoked in 1 training step. For every GPU kernel we show the direction (fprop, bprop), name of the layer, name of the operation, and the input tensor shapes / matrix dimensions for the operation. PyProf provides a lot of additional information for every GPU kernel e.g. grid dimensions, block dimensions, silicon time, datatypes, flops, bytes, tensor core usage and so on.
Zero out the gradients.
At the beginning of an iteration, we zero out the gradients.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 1 | fprop | Zero_Grad | zero_ | [148,512] | modern::vectorized_elementwise_kernel |
| 2 | fprop | Zero_Grad | zero_ | [512,512,5] | modern::vectorized_elementwise_kernel |
| 3 | fprop | Zero_Grad | zero_ | [512] | modern::vectorized_elementwise_kernel |
| 4 | fprop | Zero_Grad | zero_ | [512] | modern::vectorized_elementwise_kernel |
| 5 | fprop | Zero_Grad | zero_ | [512] | modern::vectorized_elementwise_kernel |
| 6 | fprop | Zero_Grad | zero_ | [512,512,5] | modern::vectorized_elementwise_kernel |
| 7 | fprop | Zero_Grad | zero_ | [512] | modern::vectorized_elementwise_kernel |
| 8 | fprop | Zero_Grad | zero_ | [512] | modern::vectorized_elementwise_kernel |
| 9 | fprop | Zero_Grad | zero_ | [512] | modern::vectorized_elementwise_kernel |
| 10 | fprop | Zero_Grad | zero_ | [512,512,5] | modern::vectorized_elementwise_kernel |
| 11 | fprop | Zero_Grad | zero_ | [512] | modern::vectorized_elementwise_kernel |
| 12 | fprop | Zero_Grad | zero_ | [512] | modern::vectorized_elementwise_kernel |
| 13 | fprop | Zero_Grad | zero_ | [512] | modern::vectorized_elementwise_kernel |
| 14 | fprop | Zero_Grad | zero_ | [1024,512] | modern::vectorized_elementwise_kernel |
| 15 | fprop | Zero_Grad | zero_ | [1024,256] | modern::vectorized_elementwise_kernel |
| 16 | fprop | Zero_Grad | zero_ | [1024] | modern::vectorized_elementwise_kernel |
| 17 | fprop | Zero_Grad | zero_ | [1024] | modern::vectorized_elementwise_kernel |
| 18 | fprop | Zero_Grad | zero_ | [1024,512] | modern::vectorized_elementwise_kernel |
| 19 | fprop | Zero_Grad | zero_ | [1024,256] | modern::vectorized_elementwise_kernel |
| 20 | fprop | Zero_Grad | zero_ | [1024] | modern::vectorized_elementwise_kernel |
| 21 | fprop | Zero_Grad | zero_ | [1024] | modern::vectorized_elementwise_kernel |
| 22 | fprop | Zero_Grad | zero_ | [256,80] | modern::vectorized_elementwise_kernel |
| 23 | fprop | Zero_Grad | zero_ | [256,256] | modern::vectorized_elementwise_kernel |
| 24 | fprop | Zero_Grad | zero_ | [4096,768] | modern::vectorized_elementwise_kernel |
| 25 | fprop | Zero_Grad | zero_ | [4096,1024] | modern::vectorized_elementwise_kernel |
| 26 | fprop | Zero_Grad | zero_ | [4096] | modern::vectorized_elementwise_kernel |
| 27 | fprop | Zero_Grad | zero_ | [4096] | modern::vectorized_elementwise_kernel |
| 28 | fprop | Zero_Grad | zero_ | [128,1024] | modern::vectorized_elementwise_kernel |
| 29 | fprop | Zero_Grad | zero_ | [128,512] | modern::vectorized_elementwise_kernel |
| 30 | fprop | Zero_Grad | zero_ | [1,128] | modern::vectorized_elementwise_kernel |
| 31 | fprop | Zero_Grad | zero_ | [32,2,31] | modern::vectorized_elementwise_kernel |
| 32 | fprop | Zero_Grad | zero_ | [128,32] | modern::vectorized_elementwise_kernel |
| 33 | fprop | Zero_Grad | zero_ | [4096,1536] | modern::vectorized_elementwise_kernel |
| 34 | fprop | Zero_Grad | zero_ | [4096,1024] | modern::vectorized_elementwise_kernel |
| 35 | fprop | Zero_Grad | zero_ | [4096] | modern::vectorized_elementwise_kernel |
| 36 | fprop | Zero_Grad | zero_ | [4096] | modern::vectorized_elementwise_kernel |
| 37 | fprop | Zero_Grad | zero_ | [80,1536] | modern::vectorized_elementwise_kernel |
| 38 | fprop | Zero_Grad | zero_ | [80] | modern::vectorized_elementwise_kernel |
| 39 | fprop | Zero_Grad | zero_ | [1,1536] | modern::vectorized_elementwise_kernel |
| 40 | fprop | Zero_Grad | zero_ | [1] | modern::vectorized_elementwise_kernel |
| 41 | fprop | Zero_Grad | zero_ | [512,80,5] | modern::vectorized_elementwise_kernel |
| 42 | fprop | Zero_Grad | zero_ | [512] | modern::vectorized_elementwise_kernel |
| 43 | fprop | Zero_Grad | zero_ | [512] | modern::vectorized_elementwise_kernel |
| 44 | fprop | Zero_Grad | zero_ | [512] | modern::vectorized_elementwise_kernel |
| 45 | fprop | Zero_Grad | zero_ | [512,512,5] | modern::vectorized_elementwise_kernel |
| 46 | fprop | Zero_Grad | zero_ | [512] | modern::vectorized_elementwise_kernel |
| 47 | fprop | Zero_Grad | zero_ | [512] | modern::vectorized_elementwise_kernel |
| 48 | fprop | Zero_Grad | zero_ | [512] | modern::vectorized_elementwise_kernel |
| 49 | fprop | Zero_Grad | zero_ | [512,512,5] | modern::vectorized_elementwise_kernel |
| 50 | fprop | Zero_Grad | zero_ | [512] | modern::vectorized_elementwise_kernel |
| 51 | fprop | Zero_Grad | zero_ | [512] | modern::vectorized_elementwise_kernel |
| 52 | fprop | Zero_Grad | zero_ | [512] | modern::vectorized_elementwise_kernel |
| 53 | fprop | Zero_Grad | zero_ | [512,512,5] | modern::vectorized_elementwise_kernel |
| 54 | fprop | Zero_Grad | zero_ | [512] | modern::vectorized_elementwise_kernel |
| 55 | fprop | Zero_Grad | zero_ | [512] | modern::vectorized_elementwise_kernel |
| 56 | fprop | Zero_Grad | zero_ | [512] | modern::vectorized_elementwise_kernel |
| 57 | fprop | Zero_Grad | zero_ | [80,512,5] | modern::vectorized_elementwise_kernel |
| 58 | fprop | Zero_Grad | zero_ | [80] | modern::vectorized_elementwise_kernel |
| 59 | fprop | Zero_Grad | zero_ | [80] | modern::vectorized_elementwise_kernel |
| 60 | fprop | Zero_Grad | zero_ | [80] | modern::vectorized_elementwise_kernel |
Kernels 61 and 62 calculate the maximum sentence length in a batch. Kernel 63 copies the target padded mel spectrogram to the GPU which is used to calculate the loss.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 61 | fprop | MaxLen | max | T=[(64,)] | kernelReduceAll |
| 62 | fprop | MaxLen | max | T=[(64,)] | modern::vectorized_elementwise_kernel |
| 63 | fprop | - | to | [64,80,98] | legacy::elementwise_kernel |
Encoder
The network is composed of an encoder and a decoder with attention. The encoder converts a character sequence into a hidden feature representation, which the decoder consumes to predict a spectrogram. The encoder consists of a character embedding layer, 3 1-D convolution layers and a bi-directional LSTM layer.
Encoder: Character Embedding, 3 Convolution Layers
Kernel 64 corresponds to the character embedding. Note that
the input sentence "In his defense" has 14 characters and the
batch_size is 64. The embedding table has the shape [n_symbols, symbols_embedding_dim].
Kernels 65 through 91 correspond to the three convolution layers. For each
convolution the input shape [N,C,H,W] is [64,512,1,14], the number
of filters K is encoder_embedding_dim i.e. 512, the kernel size
[R,S] is [1,encoder_kernel_size] i.e. [1,5] and the padding
[ph,pw] is [0,2]. The output shape [N,K,P,Q] is [64,512,1,14].
Each convolution is followed by batch normalization, ReLU and dropout.
Kernels 71, 80 and 89 correspond to scalar additions 1+1, and I am
not sure of their purpose.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 64 | fprop | Embedding | embedding | [64,14];[148,512] | indexSelectLargeIndex |
| 65 | fprop | Encoder:Conv_1 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | modern::unrolled_elementwise_kernel |
| 66 | fprop | Encoder:Conv_1 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 67 | fprop | Encoder:Conv_1 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 68 | fprop | Encoder:Conv_1 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | cask_cudnn::computeOffsetsKernel |
| 69 | fprop | Encoder:Conv_1 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | volta_fp16_s884cudnn_fp16_256x128_ldg8_splitK_relu_f2f_exp_small_nhwc2nchw_tn_v1 |
| 70 | fprop | Encoder:Conv_1 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | modern::unrolled_elementwise_kernel |
| 71 | fprop | Encoder:Conv_1 | __add__ | [];[] | modern::vectorized_elementwise_kernel |
| 72 | fprop | Encoder:Conv_1 | batch_norm | [64,512,14] | cudnn::bn_fw_tr_1C11_singleread_fp16 |
| 73 | fprop | Encoder:Conv_1 | relu | [64,512,14] | modern::vectorized_elementwise_kernel |
| 74 | fprop | Encoder:Conv_1 | dropout | [64,512,14] | fused_dropout_kernel_vec |
| 75 | fprop | Encoder:Conv_2 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 76 | fprop | Encoder:Conv_2 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 77 | fprop | Encoder:Conv_2 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | cask_cudnn::computeOffsetsKernel |
| 78 | fprop | Encoder:Conv_2 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | volta_fp16_s884cudnn_fp16_256x128_ldg8_splitK_relu_f2f_exp_small_nhwc2nchw_tn_v1 |
| 79 | fprop | Encoder:Conv_2 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | modern::unrolled_elementwise_kernel |
| 80 | fprop | Encoder:Conv_2 | __add__ | [];[] | modern::vectorized_elementwise_kernel |
| 81 | fprop | Encoder:Conv_2 | batch_norm | [64,512,14] | cudnn::bn_fw_tr_1C11_singleread_fp16 |
| 82 | fprop | Encoder:Conv_2 | relu | [64,512,14] | modern::vectorized_elementwise_kernel |
| 83 | fprop | Encoder:Conv_2 | dropout | [64,512,14] | fused_dropout_kernel_vec |
| 84 | fprop | Encoder:Conv_3 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 85 | fprop | Encoder:Conv_3 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 86 | fprop | Encoder:Conv_3 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | cask_cudnn::computeOffsetsKernel |
| 87 | fprop | Encoder:Conv_3 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | volta_fp16_s884cudnn_fp16_256x128_ldg8_splitK_relu_f2f_exp_small_nhwc2nchw_tn_v1 |
| 88 | fprop | Encoder:Conv_3 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | modern::unrolled_elementwise_kernel |
| 89 | fprop | Encoder:Conv_3 | __add__ | [];[] | modern::vectorized_elementwise_kernel |
| 90 | fprop | Encoder:Conv_3 | batch_norm | [64,512,14] | cudnn::bn_fw_tr_1C11_singleread_fp16 |
| 91 | fprop | Encoder:Conv_3 | relu | [64,512,14] | modern::vectorized_elementwise_kernel |
| 92 | fprop | Encoder:Conv_3 | dropout | [64,512,14] | fused_dropout_kernel_vec |
Encoder: Bidirectional LSTM
Kernels 95 through 169 correspond to the bi-directional LSTM layer. It
contains 512 units, 256 in each direction. The matrix multiplication
(GEMM) in a LSTM cell can be broken down into two components, a recurrent
component which depends on the hidden state H, and a non-recurrent
component which depends on the input X. The recurrent component has
to be performed sequentially while the non-recurrent component can
be done in parallel. In addition, the non-recurrent component for
both directions can be combined. In our input, the sequence length
(number of characters in the input sentence) is 14, which results in
14 recurrent GEMMs in each direction plus 14 non-recurrent GEMMs for a
total of 42 GEMM kernels. These kernels have the name volta_fp16_*
in the table below. A LSTM cell has many pointwise (elementwise)
operations e.g. sigmoid, tanh etc. With our input, we get 28
LSTM_elementWise_fp kernels, 14 in each direction. Kernels 93, 94
and 170 correspond to pack_padded_sequence, flatten_parameters, and
pad_packed_sequence function calls respectively. These functions are
not strictly required but using them with a GPU can result in faster
execution.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 93 | fprop | Encoder | _pack_padded_sequence | na=na, | modern::unrolled_elementwise_kernel |
| 94 | fprop | Encoder | _cudnn_rnn_flatten_weight | na=na, | modern::vectorized_elementwise_kernel |
| 95 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | modern::vectorized_elementwise_kernel |
| 96 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | transpose_kernel |
| 97 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | transpose_kernel |
| 98 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | transpose_kernel |
| 99 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | transpose_kernel |
| 100 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 101 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 102 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 103 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 104 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 105 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 106 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 107 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 108 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 109 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 110 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 111 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 112 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 113 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 114 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 115 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 116 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 117 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 118 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 119 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 120 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 121 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 122 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 123 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 124 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 125 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 126 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 127 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 128 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 129 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 130 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 131 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 132 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 133 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 134 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 135 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 136 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 137 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 138 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 139 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 140 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 141 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 142 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 143 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 144 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 145 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 146 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 147 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 148 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 149 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 150 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 151 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 152 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 153 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 154 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 155 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 156 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 157 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 158 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 159 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 160 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 161 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 162 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 163 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 164 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 165 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 166 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 167 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 168 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 169 | fprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_fp |
| 170 | fprop | Encoder | _pad_packed_sequence | na=na, | modern::vectorized_elementwise_kernel |
Decoder
The decoder is an autoregressive (previous output frame is used to compute the current output frame) recurrent neural network which predicts a mel spectrogram, one frame at a time. This autoregressive procedure is followed during inference. However, during training, we feed the target previous frame (available from labelled data), instead of the frame generated by the network, to compute the current output frame.
Decoder: Prepare inputs (from labelled data)
Kernel 171 corresponds to getting an all zeros frame to use as the first
decoder input. The shape of a frame is [batch_size,n_mel_channels]
i.e. [64,80]. Kernel 172 corresponds to concatenating the first all
zeros frame to the labelled data (target). The shape of the labelled data
is [frames,batch_size,n_mel_channels] i.e. [98,64,80]. The number of
frames depends on the length of the audio (in seconds), sampling_rate,
hop_length and win_length.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 171 | fprop | Decoder | zero_ | [64,80] | modern::vectorized_elementwise_kernel |
| 172 | fprop | Decoder:Concat | cat | [1,64,80];[98,64,80] | modern::unrolled_elementwise_kernel |
Decoder: PreNet
During inference, the PreNet is the first stage of the decoder and is called in an autoregressive fashion i.e. for every frame. During training, instead of calling the PreNet for every labelled (target) frame, a performance optimization is to call the PreNet just once, for all the frames generated above. The PreNet is a simple two layer MLP, each with 256 units, ReLU activation and dropout. The output of the PreNet (one frame at a time) is then used to generate the target frames (one frame at a time).
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 173 | fprop | Decoder:PreNet | linear | M=256,N=(99,64),K=80 | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_stages_32x1_tn |
| 174 | fprop | Decoder:PreNet | relu | [99,64,256] | modern::vectorized_elementwise_kernel |
| 175 | fprop | Decoder:PreNet | dropout | [99,64,256] | fused_dropout_kernel_vec |
| 176 | fprop | Decoder:PreNet | linear | M=256,N=(99,64),K=256 | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_tn |
| 177 | fprop | Decoder:PreNet | relu | [99,64,256] | modern::vectorized_elementwise_kernel |
| 178 | fprop | Decoder:PreNet | dropout | [99,64,256] | fused_dropout_kernel_vec |
Decoder: State initialization
Kernels 179 through 183 calculate the attention mask. Kernels 184 through 190 zero out the hidden state of the first LSTM, the cell state of the first LSTM, the hidden state of the second LSTM, the cell state of the second LSTM, the initial attention weights, the cummulative attention weights and the attention context respectively.
Tacotron uses location sensitive attention. The equation for the scoring mechanism (Eq. 9 in the paper) is given by,
Here, $i$ refers to the $i$-th frame (decoder step) and $j$ is an
index into the encoder state. The second term of the equation,
$Vh_j$, does not depend on the decoder step and can be computed
ahead of time for all $j$. The encoder state, $h$, has the shape
[batch_size,sequence_length,lstm_hidden_state] i.e. [64,14,512].
Kernels 191 and 192 correspond to the operation, $Vh$.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 179 | fprop | Decoder:Init | max | T=[(64,)] | kernelReduceAll |
| 180 | fprop | Decoder:Init | max | T=[(64,)] | modern::vectorized_elementwise_kernel |
| 181 | fprop | Decoder:Init | arange | T=[(14,)] | elementwise_kernel_with_index |
| 182 | fprop | Decoder:Init | __lt__ | [14];[64,1] | modern::unrolled_elementwise_kernel |
| 183 | fprop | Decoder:Init | __invert__ | [64,14] | modern::vectorized_elementwise_kernel |
| 184 | fprop | Decoder:Init | zero_ | [64,1024] | modern::vectorized_elementwise_kernel |
| 185 | fprop | Decoder:Init | zero_ | [64,1024] | modern::vectorized_elementwise_kernel |
| 186 | fprop | Decoder:Init | zero_ | [64,1024] | modern::vectorized_elementwise_kernel |
| 187 | fprop | Decoder:Init | zero_ | [64,1024] | modern::vectorized_elementwise_kernel |
| 188 | fprop | Decoder:Init | zero_ | [64,14] | modern::vectorized_elementwise_kernel |
| 189 | fprop | Decoder:Init | zero_ | [64,14] | modern::vectorized_elementwise_kernel |
| 190 | fprop | Decoder:Init | zero_ | [64,512] | modern::vectorized_elementwise_kernel |
| 191 | fprop | Decoder:Init:Encoder_Output | bias | M=128,N=(64,14) | modern::unrolled_elementwise_kernel |
| 192 | fprop | Decoder:Init:Encoder_Output | linear | M=128,N=(64,14),K=512 | turing_fp16_s1688gemm_fp16_64x64_sliced1x4_ldg8_f2f_tn |
Decoder: LSTM, Location Sensitive Attention, Linear Projection, Stop Token
Kernels 193 through 226 correspond to predicting one frame of the mel spectrogram. Since, our example input has 98 frames, we get a total of $34 \times 98 = 3332$ kernels. The output of the PreNet (one frame) is concatenated with the attention context vector. Kernel 193 corresponds to this operation. The concatenated tensor is fed to a LSTM cell with 1024 hidden units with dropout. Kernels 194-197 correspond to this operation. Kernels 198-213 correspond to the location sensitive attention.
The scoring function proposed in content based attention, is given by,
Location sensitive attention extends this by taking into account
the alignment (a.k.a attention weights, $\alpha$) produced by the
previous step and the cummulative attention weights (running sum of the
previous attention weights). The attention weights and cummulative
attention weights have the shape [batch_size,sequence_length]
i.e. [64,14]. The attention and cummulative attention weights are
unsqueezed and concatenated in kernel 198.
Location features are computed using 32 1D convolution filters
of length 31 (kernels 201-204). The input shape [N,C,W] is
[batch_size,2,sequence_length] i.e. [64,2,14], the number of filters
K is attention_location_n_filters i.e. 32, the filter size [R,S]
is [1,attention_location_kernel_size] i.e. 31, the padding [ph,pw]
is [0,31] so that Q = W = sequence_length. The output shape [N,K,Q]
is [64,32,14] and corresponds to $f_i$ in the equation below.
The scoring function used in location sensitive attention is given by,
Here, $i$ refers to the $i$-th frame (decoder step) and $j$ is an index into the encoder state. The third term of the equation, $Uf_i$, is computed in kernels 205 and 206. The first term of the equation, $Ws_{i-1}$, uses the output of the LSTM cell and is computed in kernels 199 and 200. Recall, that the second term of the equation was computed earlier.
Once, we have all the three terms, we add them up (kernels 207 and 208). Kernels 209 and 210 correspond to tanh and matrix-vector multiplication. This gives us the attention scores. Since sentences in a batch have different lengths, kernels 211 applies a mask to the attention scores. Kernel 212 corresponds to the softmax operation which normalizes the scores. Using the terminology from the paper, we calculate the glimpse, $g_i$, in kernel 213, which is the attention context vector.
In kernel 214, we accumulate the new attention weights which will be used in the next step (frame). In kernel 215, we concatenate the output of the first LSTM and the attention context and feed it to another LSTM cell with 1024 hidden units with dropout (kernels 216-219).
Finally, we concatenate the LSTM output and the attention context (kernel
220). This output is passed through a linear layer (kernels 221-223) to
produce a spectrogram frame, whose shape is [batch_size,n_mel_channels]
i.e. [64,80]. In parallel, the concatenated output is passed through
another linear layer (kernels 224-226) to predict the probability that
the output sequence has completed i.e. a stop token. The output of
this linear layer has the shape [batch_size,1] i.e. [64,1].
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 193 | fprop | Decoder:Decoder,Context | cat | [64,256];[64,512] | CatArrayBatchedCopy |
| 194 | fprop | Decoder:LSTM1 | forward | gemm=layer,M=4096,N=64,K=768 | turing_fp16_s1688gemm_fp16_128x64_sliced1x2_ldg8_f2f_tn |
| 195 | fprop | Decoder:LSTM1 | forward | gemm=recur,M=4096,N=64,K=1024 | turing_fp16_s1688gemm_fp16_128x64_sliced1x2_ldg8_f2f_tn |
| 196 | fprop | Decoder:LSTM1 | forward | cell=LSTMCell,X=768,H=1024,B=64 | kernel::lstm_cell_forward |
| 197 | fprop | Decoder:LSTM1 | dropout | [64,1024] | fused_dropout_kernel_vec |
| 198 | fprop | Decoder:Weights,Cum_weights | cat | [64,1,14];[64,1,14] | CatArrayBatchedCopy |
| 199 | fprop | Decoder:Attention:Score:Generator | linear | M=128,N=(64,1),K=1024 | cutlass::Kernel |
| 200 | fprop | Decoder:Attention:Score:Generator | linear | M=128,N=(64,1),K=1024 | splitKreduce_kernel |
| 201 | fprop | Decoder:Attention:Score:Location | conv1d | N=64,C=2,H=1,W=14,K=32,P=1,Q=14,R=1,S=31,ph=0,pw=15 | nchwToNhwcKernel |
| 202 | fprop | Decoder:Attention:Score:Location | conv1d | N=64,C=2,H=1,W=14,K=32,P=1,Q=14,R=1,S=31,ph=0,pw=15 | nchwToNhwcKernel |
| 203 | fprop | Decoder:Attention:Score:Location | conv1d | N=64,C=2,H=1,W=14,K=32,P=1,Q=14,R=1,S=31,ph=0,pw=15 | xmma_new::gemm::kernel |
| 204 | fprop | Decoder:Attention:Score:Location | conv1d | N=64,C=2,H=1,W=14,K=32,P=1,Q=14,R=1,S=31,ph=0,pw=15 | nhwcToNchwKernel |
| 205 | fprop | Decoder:Attention:Score:Location | bias | M=128,N=(64,14) | modern::unrolled_elementwise_kernel |
| 206 | fprop | Decoder:Attention:Score:Location | linear | M=128,N=(64,14),K=32 | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_tn |
| 207 | fprop | Decoder:Attention:Score | __add__ | [64,1,128];[64,14,128] | modern::unrolled_elementwise_kernel |
| 208 | fprop | Decoder:Attention:Score | __add__ | [64,14,128];[64,14,128] | modern::vectorized_elementwise_kernel |
| 209 | fprop | Decoder:Attention:Score | tanh | [64,14,128] | modern::vectorized_elementwise_kernel |
| 210 | fprop | Decoder:Attention:Score | linear | M=1,N=(64,14),K=128 | gemv2T_kernel_val |
| 211 | fprop | Decoder:Attention | masked_fill_ | T=[(64,14),(64,14)] | kernelPointwiseApply2 |
| 212 | fprop | Decoder:Attention:Weights | softmax | [64,14] | softmax_warp_forward |
| 213 | fprop | Decoder:Attention:Context | bmm | B=64,M=512,N=1,K=14 | gemv2N_kernel |
| 214 | fprop | Decoder:Cumulative_weights | __iadd__ | [64,14];[64,14] | modern::vectorized_elementwise_kernel |
| 215 | fprop | Decoder:LSTM1,Context | cat | [64,1024];[64,512] | CatArrayBatchedCopy |
| 216 | fprop | Decoder:LSTM2 | forward | gemm=layer,M=4096,N=64,K=1536 | turing_fp16_s1688gemm_fp16_128x64_sliced1x2_ldg8_f2f_tn |
| 217 | fprop | Decoder:LSTM2 | forward | gemm=recur,M=4096,N=64,K=1024 | turing_fp16_s1688gemm_fp16_128x64_sliced1x2_ldg8_f2f_tn |
| 218 | fprop | Decoder:LSTM2 | forward | cell=LSTMCell,X=1536,H=1024,B=64 | kernel::lstm_cell_forward |
| 219 | fprop | Decoder:LSTM2 | dropout | [64,1024] | fused_dropout_kernel_vec |
| 220 | fprop | Decoder:LSTM2,Context | cat | [64,1024];[64,512] | CatArrayBatchedCopy |
| 221 | fprop | Decoder:Output | bias | M=80,N=64 | modern::unrolled_elementwise_kernel |
| 222 | fprop | Decoder:Output | linear | M=80,N=64,K=1536 | cutlass::Kernel |
| 223 | fprop | Decoder:Output | linear | M=80,N=64,K=1536 | splitKreduce_kernel |
| 224 | fprop | Decoder:Gate | bias | M=1,N=64 | modern::unrolled_elementwise_kernel |
| 225 | fprop | Decoder:Gate | linear | M=1,N=64,K=1536 | gemv2T_kernel_val |
| 226 | fprop | Decoder:Gate | linear | M=1,N=64,K=1536 | splitKreduce_kernel |
Decoder: Output Stacking
At every step, the decoder outputs a mel-spectrogram frame of shape
[batch_size,n_mel_channels] i.e. [64,80] and a stop token of
shape [batch_size] i.e. [64]. In kernels 3526 and 3527, we stack
the stop tokens from all steps and make them contiguous to give us a
tensor of shape [batch_size,frames] i.e. [64,98]. Likewise,
in kernels 3528 and 3529, we stack the spectrogram frame from
all steps and make them contiguous to give us a tensor of shape
[batch_size,frames,n_mel_channels] i.e. [64,98,80].
During every step, we calculate the alignment (attention weights) which
has the shape [batch_size,sequence_length]. In kernel 3525, we stack
the alignments from all the steps. This operation is not required for
training and is probably used for visualization.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 3525 | fprop | Decoder:Alignment | stack | T=[(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14),(64,14)] | CatArrayBatchedCopy |
| 3526 | fprop | Decoder:Stop_token | stack | T=[(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,),(64,)] | CatArrayBatchedCopy |
| 3527 | fprop | Decoder:Stop_token | contiguous | T=(64,98) | modern::unrolled_elementwise_kernel |
| 3528 | fprop | Decoder:Spectrogram | stack | T=[(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80),(64,80)] | CatArrayBatchedCopy |
| 3529 | fprop | Decoder:Spectrogram | contiguous | T=(64,98,80) | modern::unrolled_elementwise_kernel |
Decoder: PostNet
The stacked and contiguous mel spectrograms from the previous step are
fed to the PostNet. The PostNet block has 5 convolution layers with a
residual connection. Each convolution is followed by batch normalization,
tanh activation and dropout. Tanh activation is present on all but
the last layer.
Kernels 3530 through 3575 correspond to the five convolution
layers. The input to the first convolution [N,C,H,W] is
[batch_size,n_mel_channels,1,frames] i.e. [64,80,1,98],
the number of filters K is 512, the kernel size
[R,S] is [1,5] and the padding [ph,pw] is [0,2]. The output
[N,K,P,Q] is [64,512,1,98]. For the second, third and fourth
convolution both the input and output shape is [64,512,1,98]. The
number of filters, kernel size, padding is the same as above. For the
fifth convolution, the output shape is [64,80,1,98]. The number of
filters is 80. The kernel size and padding is the same as above.
Kernel 3576 corresponds to the residual connection.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 3530 | fprop | PostNet:Conv1 | conv1d | N=64,C=80,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | modern::unrolled_elementwise_kernel |
| 3531 | fprop | PostNet:Conv1 | conv1d | N=64,C=80,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 3532 | fprop | PostNet:Conv1 | conv1d | N=64,C=80,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 3533 | fprop | PostNet:Conv1 | conv1d | N=64,C=80,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | xmma_new::gemm::kernel |
| 3534 | fprop | PostNet:Conv1 | conv1d | N=64,C=80,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nhwcToNchwKernel |
| 3535 | fprop | PostNet:Conv1 | conv1d | N=64,C=80,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | modern::unrolled_elementwise_kernel |
| 3536 | fprop | PostNet:Conv1 | __add__ | [];[] | modern::vectorized_elementwise_kernel |
| 3537 | fprop | PostNet:Conv1 | batch_norm | [64,512,98] | cudnn::bn_fw_tr_1C11_singleread_fp16 |
| 3538 | fprop | PostNet:Conv1 | tanh | [64,512,98] | modern::vectorized_elementwise_kernel |
| 3539 | fprop | PostNet:Conv1 | dropout | [64,512,98] | fused_dropout_kernel_vec |
| 3540 | fprop | PostNet:Conv2 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 3541 | fprop | PostNet:Conv2 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 3542 | fprop | PostNet:Conv2 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | cask_cudnn::computeOffsetsKernel |
| 3543 | fprop | PostNet:Conv2 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | volta_fp16_s884cudnn_fp16_256x128_ldg8_splitK_relu_f2f_exp_small_nhwc2nchw_tn_v1 |
| 3544 | fprop | PostNet:Conv2 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | modern::unrolled_elementwise_kernel |
| 3545 | fprop | PostNet:Conv2 | __add__ | [];[] | modern::vectorized_elementwise_kernel |
| 3546 | fprop | PostNet:Conv2 | batch_norm | [64,512,98] | cudnn::bn_fw_tr_1C11_singleread_fp16 |
| 3547 | fprop | PostNet:Conv2 | tanh | [64,512,98] | modern::vectorized_elementwise_kernel |
| 3548 | fprop | PostNet:Conv2 | dropout | [64,512,98] | fused_dropout_kernel_vec |
| 3549 | fprop | PostNet:Conv3 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 3550 | fprop | PostNet:Conv3 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 3551 | fprop | PostNet:Conv3 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | cask_cudnn::computeOffsetsKernel |
| 3552 | fprop | PostNet:Conv3 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | volta_fp16_s884cudnn_fp16_256x128_ldg8_splitK_relu_f2f_exp_small_nhwc2nchw_tn_v1 |
| 3553 | fprop | PostNet:Conv3 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | modern::unrolled_elementwise_kernel |
| 3554 | fprop | PostNet:Conv3 | __add__ | [];[] | modern::vectorized_elementwise_kernel |
| 3555 | fprop | PostNet:Conv3 | batch_norm | [64,512,98] | cudnn::bn_fw_tr_1C11_singleread_fp16 |
| 3556 | fprop | PostNet:Conv3 | tanh | [64,512,98] | modern::vectorized_elementwise_kernel |
| 3557 | fprop | PostNet:Conv3 | dropout | [64,512,98] | fused_dropout_kernel_vec |
| 3558 | fprop | PostNet:Conv4 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 3559 | fprop | PostNet:Conv4 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 3560 | fprop | PostNet:Conv4 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | cask_cudnn::computeOffsetsKernel |
| 3561 | fprop | PostNet:Conv4 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | volta_fp16_s884cudnn_fp16_256x128_ldg8_splitK_relu_f2f_exp_small_nhwc2nchw_tn_v1 |
| 3562 | fprop | PostNet:Conv4 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | modern::unrolled_elementwise_kernel |
| 3563 | fprop | PostNet:Conv4 | __add__ | [];[] | modern::vectorized_elementwise_kernel |
| 3564 | fprop | PostNet:Conv4 | batch_norm | [64,512,98] | cudnn::bn_fw_tr_1C11_singleread_fp16 |
| 3565 | fprop | PostNet:Conv4 | tanh | [64,512,98] | modern::vectorized_elementwise_kernel |
| 3566 | fprop | PostNet:Conv4 | dropout | [64,512,98] | fused_dropout_kernel_vec |
| 3567 | fprop | PostNet:Conv5 | conv1d | N=64,C=512,H=1,W=98,K=80,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 3568 | fprop | PostNet:Conv5 | conv1d | N=64,C=512,H=1,W=98,K=80,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 3569 | fprop | PostNet:Conv5 | conv1d | N=64,C=512,H=1,W=98,K=80,P=1,Q=98,R=1,S=5,ph=0,pw=2 | cask_cudnn::computeOffsetsKernel |
| 3570 | fprop | PostNet:Conv5 | conv1d | N=64,C=512,H=1,W=98,K=80,P=1,Q=98,R=1,S=5,ph=0,pw=2 | turing_fp16_s1688cudnn_fp16_256x128_ldg8_relu_f2f_exp_medium_nhwc_tn_v1 |
| 3571 | fprop | PostNet:Conv5 | conv1d | N=64,C=512,H=1,W=98,K=80,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nhwcToNchwKernel |
| 3572 | fprop | PostNet:Conv5 | conv1d | N=64,C=512,H=1,W=98,K=80,P=1,Q=98,R=1,S=5,ph=0,pw=2 | modern::unrolled_elementwise_kernel |
| 3573 | fprop | PostNet:Conv5 | __add__ | [];[] | modern::vectorized_elementwise_kernel |
| 3574 | fprop | PostNet:Conv5 | batch_norm | [64,80,98] | cudnn::bn_fw_tr_1C11_singleread_fp16 |
| 3575 | fprop | PostNet:Conv5 | dropout | [64,80,98] | fused_dropout_kernel_vec |
| 3576 | fprop | PostNet:Residual | __add__ | [64,80,98];[64,80,98] | modern::unrolled_elementwise_kernel |
Output Postprocessing
Similar to kernels 179-183, kernels 3577-3581 calculate the mask. Kernels 3582, 3583, 3584 apply the mask to the mel spectrogram before the PostNet, the mel spectrogram after the PostNet and to the stop tokens respectively. Kernels 3585-3588 convert the datatype of the mel spectrogram before the PostNet, mel spectrogram after the PostNet, stop token and alignment tensors respectively from float16 to float32 before feeding it to the loss layers. The alignment tensor is not used for loss calculation and therefore, kernel 3588 is not required.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 3577 | fprop | - | max | T=[(64,)] | kernelReduceAll |
| 3578 | fprop | - | max | T=[(64,)] | modern::vectorized_elementwise_kernel |
| 3579 | fprop | - | arange | T=[(98,)] | elementwise_kernel_with_index |
| 3580 | fprop | - | __lt__ | [98];[64,1] | modern::unrolled_elementwise_kernel |
| 3581 | fprop | - | __invert__ | [64,98] | modern::vectorized_elementwise_kernel |
| 3582 | fprop | - | masked_fill_ | T=[(64,80,98),(64,80,98)] | kernelPointwiseApply2 |
| 3583 | fprop | - | masked_fill_ | T=[(64,80,98),(64,80,98)] | kernelPointwiseApply2 |
| 3584 | fprop | - | masked_fill_ | T=[(64,98),(64,98)] | kernelPointwiseApply2 |
| 3585 | fprop | - | to | [64,80,98] | legacy::elementwise_kernel |
| 3586 | fprop | - | to | [64,80,98] | legacy::elementwise_kernel |
| 3587 | fprop | - | to | [64,98] | legacy::elementwise_kernel |
| 3588 | fprop | - | to | [64,98,14] | legacy::elementwise_kernel |
Loss
Kernels 3589 and 3590 calculate the MSE loss due to the mel spectrogram before the PostNet. Kernels 3591 and 3592 calculate the MSE loss due to the mel spectrogram after the PostNet. Kernel 3593 sums up the two losses. Kernels 3594-3608 correspond to the BCE loss from the stop token prediction. Kernel 3609 sums up all the losses. Kernel 3610 most likely corresponds to loss scaling by a factor.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 3589 | fprop | Loss:Mel | mse_loss | T=(64,80,98)red=mean, | modern::unrolled_elementwise_kernel |
| 3590 | fprop | Loss:Mel | mse_loss | T=(64,80,98)red=mean, | reduce_kernel |
| 3591 | fprop | Loss:Mel | mse_loss | T=(64,80,98)red=mean, | modern::unrolled_elementwise_kernel |
| 3592 | fprop | Loss:Mel | mse_loss | T=(64,80,98)red=mean, | reduce_kernel |
| 3593 | fprop | Loss:Mel | __add__ | [];[] | modern::vectorized_elementwise_kernel |
| 3594 | fprop | Loss:Gate | binary_cross_entropy_with_logits | T=[(6272,1),(6272,1)] | modern::vectorized_elementwise_kernel |
| 3595 | fprop | Loss:Gate | binary_cross_entropy_with_logits | T=[(6272,1),(6272,1)] | modern::vectorized_elementwise_kernel |
| 3596 | fprop | Loss:Gate | binary_cross_entropy_with_logits | T=[(6272,1),(6272,1)] | modern::vectorized_elementwise_kernel |
| 3597 | fprop | Loss:Gate | binary_cross_entropy_with_logits | T=[(6272,1),(6272,1)] | modern::vectorized_elementwise_kernel |
| 3598 | fprop | Loss:Gate | binary_cross_entropy_with_logits | T=[(6272,1),(6272,1)] | modern::vectorized_elementwise_kernel |
| 3599 | fprop | Loss:Gate | binary_cross_entropy_with_logits | T=[(6272,1),(6272,1)] | modern::vectorized_elementwise_kernel |
| 3600 | fprop | Loss:Gate | binary_cross_entropy_with_logits | T=[(6272,1),(6272,1)] | modern::vectorized_elementwise_kernel |
| 3601 | fprop | Loss:Gate | binary_cross_entropy_with_logits | T=[(6272,1),(6272,1)] | modern::vectorized_elementwise_kernel |
| 3602 | fprop | Loss:Gate | binary_cross_entropy_with_logits | T=[(6272,1),(6272,1)] | modern::vectorized_elementwise_kernel |
| 3603 | fprop | Loss:Gate | binary_cross_entropy_with_logits | T=[(6272,1),(6272,1)] | modern::vectorized_elementwise_kernel |
| 3604 | fprop | Loss:Gate | binary_cross_entropy_with_logits | T=[(6272,1),(6272,1)] | modern::vectorized_elementwise_kernel |
| 3605 | fprop | Loss:Gate | binary_cross_entropy_with_logits | T=[(6272,1),(6272,1)] | modern::vectorized_elementwise_kernel |
| 3606 | fprop | Loss:Gate | binary_cross_entropy_with_logits | T=[(6272,1),(6272,1)] | modern::vectorized_elementwise_kernel |
| 3607 | fprop | Loss:Gate | binary_cross_entropy_with_logits | T=[(6272,1),(6272,1)] | modern::vectorized_elementwise_kernel |
| 3608 | fprop | Loss:Gate | binary_cross_entropy_with_logits | T=[(6272,1),(6272,1)] | reduce_kernel |
| 3609 | fprop | Loss:Total | __add__ | [];[] | modern::vectorized_elementwise_kernel |
| 3610 | fprop | - | __mul__ | [];[] | modern::vectorized_elementwise_kernel |
Back propagation: Loss
Kernels 3612 through 3620 correspond to back propagation through the loss layer.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 3611 | fprop | - | backward | T=[],[] | modern::vectorized_elementwise_kernel |
| 3612 | bprop | Loss:Total | __add__ | [];[] | modern::vectorized_elementwise_kernel |
| 3613 | bprop | Loss:Mel | __add__ | [];[] | modern::vectorized_elementwise_kernel |
| 3614 | bprop | Loss:Mel | __add__ | [];[] | modern::vectorized_elementwise_kernel |
| 3615 | bprop | Loss:Mel | __add__ | [];[] | modern::unrolled_elementwise_kernel |
| 3616 | bprop | Loss:Mel | __add__ | [];[] | modern::vectorized_elementwise_kernel |
| 3617 | bprop | Loss:Mel | mse_loss | T=(64,80,98)red=mean, | modern::vectorized_elementwise_kernel |
| 3618 | bprop | Loss:Mel | mse_loss | T=(64,80,98)red=mean, | modern::unrolled_elementwise_kernel |
| 3619 | bprop | Loss:Mel | mse_loss | T=(64,80,98)red=mean, | modern::vectorized_elementwise_kernel |
| 3620 | bprop | Loss:Mel | mse_loss | T=(64,80,98)red=mean, | modern::unrolled_elementwise_kernel |
Kernels 3621-3623 most likely correspond to back propagation through the convert operations (kernels 3585-3587).
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 3621 | fprop | - | copy_ | na=na, | legacy::elementwise_kernel |
| 3622 | fprop | - | copy_ | na=na, | legacy::elementwise_kernel |
| 3623 | fprop | - | copy_ | na=na, | legacy::elementwise_kernel |
Back propagation: PostNet
Kernels 3624 through 3672 correspond to back propagation through the five convolution layers in PostNet.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 3624 | bprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3625 | bprop | PostNet:Conv5 | batch_norm | [64,80,98] | modern::vectorized_elementwise_kernel |
| 3626 | bprop | PostNet:Conv5 | __add__ | [];[] | cudnn::bn_bw_1C11_singleread_fp16 |
| 3627 | bprop | - | na=na, | reduce_kernel | |
| 3628 | bprop | PostNet:Conv5 | conv1d | N=64,C=512,H=1,W=98,K=80,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 3629 | bprop | PostNet:Conv5 | conv1d | N=64,C=512,H=1,W=98,K=80,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 3630 | bprop | PostNet:Conv5 | conv1d | N=64,C=512,H=1,W=98,K=80,P=1,Q=98,R=1,S=5,ph=0,pw=2 | xmma_new::gemm::kernel |
| 3631 | bprop | PostNet:Conv5 | conv1d | N=64,C=512,H=1,W=98,K=80,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nhwcToNchwKernel |
| 3632 | bprop | PostNet:Conv5 | conv1d | N=64,C=512,H=1,W=98,K=80,P=1,Q=98,R=1,S=5,ph=0,pw=2 | cudnn::cnn::wgrad_alg0_engine |
| 3633 | bprop | PostNet:Conv4 | tanh | [64,512,98] | modern::vectorized_elementwise_kernel |
| 3634 | bprop | PostNet:Conv4 | batch_norm | [64,512,98] | modern::vectorized_elementwise_kernel |
| 3635 | bprop | PostNet:Conv4 | __add__ | [];[] | cudnn::bn_bw_1C11_singleread_fp16 |
| 3636 | bprop | - | na=na, | reduce_kernel | |
| 3637 | bprop | PostNet:Conv4 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | cudnn::ops::scalePackedTensor_kernel |
| 3638 | bprop | PostNet:Conv4 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | cudnn::detail::dgrad_alg1_engine |
| 3639 | bprop | PostNet:Conv4 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 3640 | bprop | PostNet:Conv4 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 3641 | bprop | PostNet:Conv4 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | xmma_new::gemm::kernel |
| 3642 | bprop | PostNet:Conv4 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nhwcToNchwKernel |
| 3643 | bprop | PostNet:Conv3 | tanh | [64,512,98] | modern::vectorized_elementwise_kernel |
| 3644 | bprop | PostNet:Conv3 | batch_norm | [64,512,98] | modern::vectorized_elementwise_kernel |
| 3645 | bprop | PostNet:Conv3 | __add__ | [];[] | cudnn::bn_bw_1C11_singleread_fp16 |
| 3646 | bprop | - | na=na, | reduce_kernel | |
| 3647 | bprop | PostNet:Conv3 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | cudnn::ops::scalePackedTensor_kernel |
| 3648 | bprop | PostNet:Conv3 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | cudnn::detail::dgrad_alg1_engine |
| 3649 | bprop | PostNet:Conv3 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 3650 | bprop | PostNet:Conv3 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 3651 | bprop | PostNet:Conv3 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | xmma_new::gemm::kernel |
| 3652 | bprop | PostNet:Conv3 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nhwcToNchwKernel |
| 3653 | bprop | PostNet:Conv2 | tanh | [64,512,98] | modern::vectorized_elementwise_kernel |
| 3654 | bprop | PostNet:Conv2 | batch_norm | [64,512,98] | modern::vectorized_elementwise_kernel |
| 3655 | bprop | PostNet:Conv2 | __add__ | [];[] | cudnn::bn_bw_1C11_singleread_fp16 |
| 3656 | bprop | - | na=na, | reduce_kernel | |
| 3657 | bprop | PostNet:Conv2 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | cudnn::ops::scalePackedTensor_kernel |
| 3658 | bprop | PostNet:Conv2 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | cudnn::detail::dgrad_alg1_engine |
| 3659 | bprop | PostNet:Conv2 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 3660 | bprop | PostNet:Conv2 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 3661 | bprop | PostNet:Conv2 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | xmma_new::gemm::kernel |
| 3662 | bprop | PostNet:Conv2 | conv1d | N=64,C=512,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nhwcToNchwKernel |
| 3663 | bprop | PostNet:Conv1 | tanh | [64,512,98] | modern::vectorized_elementwise_kernel |
| 3664 | bprop | PostNet:Conv1 | batch_norm | [64,512,98] | modern::vectorized_elementwise_kernel |
| 3665 | bprop | PostNet:Conv1 | __add__ | [];[] | cudnn::bn_bw_1C11_singleread_fp16 |
| 3666 | bprop | - | na=na, | reduce_kernel | |
| 3667 | bprop | PostNet:Conv1 | conv1d | N=64,C=80,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | cudnn::ops::scalePackedTensor_kernel |
| 3668 | bprop | PostNet:Conv1 | conv1d | N=64,C=80,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | cudnn::detail::dgrad_alg1_engine |
| 3669 | bprop | PostNet:Conv1 | conv1d | N=64,C=80,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 3670 | bprop | PostNet:Conv1 | conv1d | N=64,C=80,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 3671 | bprop | PostNet:Conv1 | conv1d | N=64,C=80,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | xmma_new::gemm::kernel |
| 3672 | bprop | PostNet:Conv1 | conv1d | N=64,C=80,H=1,W=98,K=512,P=1,Q=98,R=1,S=5,ph=0,pw=2 | nhwcToNchwKernel |
Back propagation: LSTM, Location Sensitive Attention, Linear Projection, Stop Token
Our example input has 98 frames and therefore we perfrom back propagation
through the 2 LSTM layers with location sensitive attention and linear
projection layers, 98 times. The last frame invokes 53 kernels, the
first frame invokes 66 kernels and all the intermediate frames invoke
78 kernels for a total of $53 + 96\times 78 + 66 = 7607$ kernels. I am
not sure why the last and first frame behave differently. The table
below shows the kernels invoked during back propagation for one of
the intermediate frames with 78 kernels. For many kernels, we cannot
ascertain any information except the name and are shown as na.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 3727 | bprop | Decoder:Gate | linear | M=1536,N=64,K=1 | gemmk1_kernel |
| 3728 | bprop | Decoder:Gate | linear | M=1536,N=1,K=64 | gemvNSP_kernel |
| 3729 | fprop | - | na=na, | reduce_kernel | |
| 3730 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3731 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3732 | bprop | Decoder:Output | bias | M=80,N=64 | modern::unrolled_elementwise_kernel |
| 3733 | bprop | Decoder:Output | linear | M=1536,N=80,K=64 | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 3734 | bprop | Decoder:Output | bias | M=80,N=64 | modern::unrolled_elementwise_kernel |
| 3735 | bprop | Decoder:Output | linear | X=(64,1536),W=(80,1536) | cutlass::Kernel |
| 3736 | fprop | - | na=na, | reduce_kernel | |
| 3737 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3738 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3739 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3740 | fprop | - | na=na, | modern::unrolled_elementwise_kernel | |
| 3741 | fprop | - | na=na, | modern::unrolled_elementwise_kernel | |
| 3742 | bprop | Decoder:LSTM2 | dropout | [64,1024] | modern::vectorized_elementwise_kernel |
| 3743 | bprop | Decoder:LSTM2 | forward | cell=LSTMCell,X=1536,H=1024,B=64 | kernel::lstm_cell_backward |
| 3744 | bprop | Decoder:LSTM2 | forward | cell=LSTMCell,X=1536,H=1024,B=64 | reduce_kernel |
| 3745 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3746 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3747 | bprop | Decoder:LSTM2 | forward | cell=LSTMCell,X=1536,H=1024,B=64 | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_nt |
| 3748 | bprop | Decoder:LSTM2 | forward | cell=LSTMCell,X=1536,H=1024,B=64 | turing_fp16_s1688gemm_fp16_256x64_ldg8_f2f_stages_32x1_nn |
| 3749 | bprop | Decoder:LSTM2 | forward | cell=LSTMCell,X=1536,H=1024,B=64 | splitKreduce_kernel |
| 3750 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3751 | bprop | Decoder:LSTM2 | forward | cell=LSTMCell,X=1536,H=1024,B=64 | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_nt |
| 3752 | bprop | Decoder:LSTM2 | forward | cell=LSTMCell,X=1536,H=1024,B=64 | turing_fp16_s1688gemm_fp16_256x64_ldg8_f2f_stages_32x1_nn |
| 3753 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3754 | fprop | - | na=na, | modern::unrolled_elementwise_kernel | |
| 3755 | fprop | - | na=na, | modern::unrolled_elementwise_kernel | |
| 3756 | fprop | - | na=na, | modern::unrolled_elementwise_kernel | |
| 3757 | bprop | Decoder:Attention:Context | bmm | B=64,M=512,N=1,K=14 | gemmk1_kernel |
| 3758 | bprop | Decoder:Attention:Context | bmm | B=64,M=512,N=1,K=14 | gemv2T_kernel_val |
| 3759 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3760 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3761 | bprop | Decoder:Attention | masked_fill_ | T=[(64,14),(64,14)] | modern::vectorized_elementwise_kernel |
| 3762 | bprop | Decoder:Attention | masked_fill_ | T=[(64,14),(64,14)] | softmax_warp_backward |
| 3763 | bprop | Decoder:Attention:Score | linear | M=128,N=(64,14),K=1 | gemv2N_kernel |
| 3764 | bprop | Decoder:Attention:Score | linear | M=128,N=1,K=(64,14) | splitKreduce_kernel |
| 3765 | bprop | Decoder:Attention:Score | linear | X=(64,14,128),W=(1,128) | gemmk1_kernel |
| 3766 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3767 | bprop | Decoder:Attention:Score | tanh | [64,14,128] | modern::vectorized_elementwise_kernel |
| 3768 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3769 | fprop | - | na=na, | reduce_kernel | |
| 3770 | bprop | Decoder:Attention:Score:Location | linear | M=32,N=(64,14),K=128 | cutlass::Kernel |
| 3771 | bprop | Decoder:Attention:Score:Location | linear | M=32,N=128,K=(64,14) | splitKreduce_kernel |
| 3772 | bprop | Decoder:Attention:Score:Location | linear | X=(64,14,32),W=(128,32) | cutlass::Kernel |
| 3773 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3774 | bprop | Decoder:Attention:Score:Location | conv1d | N=64,C=2,H=1,W=14,K=32,P=1,Q=14,R=1,S=31,ph=0,pw=15 | modern::unrolled_elementwise_kernel |
| 3775 | bprop | Decoder:Attention:Score:Location | conv1d | N=64,C=2,H=1,W=14,K=32,P=1,Q=14,R=1,S=31,ph=0,pw=15 | fft2d_r2c_64x64 |
| 3776 | bprop | Decoder:Attention:Score:Location | conv1d | N=64,C=2,H=1,W=14,K=32,P=1,Q=14,R=1,S=31,ph=0,pw=15 | fft2d_r2c_64x64 |
| 3777 | bprop | Decoder:Attention:Score:Location | conv1d | N=64,C=2,H=1,W=14,K=32,P=1,Q=14,R=1,S=31,ph=0,pw=15 | transpose_readWrite_alignment_kernel |
| 3778 | bprop | Decoder:Attention:Score:Location | conv1d | N=64,C=2,H=1,W=14,K=32,P=1,Q=14,R=1,S=31,ph=0,pw=15 | transpose_readWrite_alignment_kernel |
| 3779 | bprop | Decoder:Attention:Score:Location | conv1d | N=64,C=2,H=1,W=14,K=32,P=1,Q=14,R=1,S=31,ph=0,pw=15 | volta_cgemm_32x32_tn |
| 3780 | bprop | Decoder:Attention:Score:Location | conv1d | N=64,C=2,H=1,W=14,K=32,P=1,Q=14,R=1,S=31,ph=0,pw=15 | transpose_readWrite_alignment_kernel |
| 3781 | bprop | Decoder:Attention:Score:Location | conv1d | N=64,C=2,H=1,W=14,K=32,P=1,Q=14,R=1,S=31,ph=0,pw=15 | fft2d_c2r_64x64 |
| 3782 | bprop | Decoder:Attention:Score:Location | conv1d | N=64,C=2,H=1,W=14,K=32,P=1,Q=14,R=1,S=31,ph=0,pw=15 | cudnn::cnn::wgrad_alg0_engine |
| 3783 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3784 | bprop | Decoder:Attention:Score:Generator | linear | M=1024,N=(64,1),K=128 | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nt |
| 3785 | bprop | Decoder:Attention:Score:Generator | linear | M=1024,N=128,K=(64,1) | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 3786 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3787 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3788 | fprop | - | na=na, | modern::unrolled_elementwise_kernel | |
| 3789 | bprop | Decoder:LSTM1 | dropout | [64,1024] | modern::vectorized_elementwise_kernel |
| 3790 | bprop | Decoder:LSTM1 | forward | cell=LSTMCell,X=768,H=1024,B=64 | kernel::lstm_cell_backward |
| 3791 | bprop | Decoder:LSTM1 | forward | cell=LSTMCell,X=768,H=1024,B=64 | reduce_kernel |
| 3792 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3793 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3794 | bprop | Decoder:LSTM1 | forward | cell=LSTMCell,X=768,H=1024,B=64 | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_nt |
| 3795 | bprop | Decoder:LSTM1 | forward | cell=LSTMCell,X=768,H=1024,B=64 | turing_fp16_s1688gemm_fp16_256x64_ldg8_f2f_stages_32x1_nn |
| 3796 | bprop | Decoder:LSTM1 | forward | cell=LSTMCell,X=768,H=1024,B=64 | splitKreduce_kernel |
| 3797 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3798 | bprop | Decoder:LSTM1 | forward | cell=LSTMCell,X=768,H=1024,B=64 | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_nt |
| 3799 | bprop | Decoder:LSTM1 | forward | cell=LSTMCell,X=768,H=1024,B=64 | turing_fp16_s1688gemm_fp16_256x64_ldg8_f2f_stages_32x1_nn |
| 3800 | bprop | Decoder:LSTM1 | forward | cell=LSTMCell,X=768,H=1024,B=64 | splitKreduce_kernel |
| 3801 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 3802 | bprop | - | Select | na=na, | modern::vectorized_elementwise_kernel |
| 3803 | bprop | - | Select | na=na, | modern::unrolled_elementwise_kernel |
| 3804 | fprop | - | na=na, | modern::vectorized_elementwise_kernel |
Back propagation: PreNet
Kernels 11284 through 11293 correspond to back propagation through the PreNet block.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 11284 | fprop | - | na=na, | modern::vectorized_elementwise_kernel | |
| 11285 | bprop | Decoder:PreNet | dropout | [99,64,256] | modern::vectorized_elementwise_kernel |
| 11286 | bprop | Decoder:PreNet | relu | [99,64,256] | modern::vectorized_elementwise_kernel |
| 11287 | bprop | Decoder:PreNet | linear | M=256,N=(99,64),K=256 | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_stages_32x1_nt |
| 11288 | bprop | Decoder:PreNet | linear | M=256,N=256,K=(99,64) | splitKreduce_kernel |
| 11289 | bprop | Decoder:PreNet | linear | X=(99,64,256),W=(256,256) | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_nn |
| 11290 | bprop | Decoder:PreNet | dropout | [99,64,256] | modern::vectorized_elementwise_kernel |
| 11291 | bprop | Decoder:PreNet | relu | [99,64,256] | modern::vectorized_elementwise_kernel |
| 11292 | bprop | Decoder:PreNet | linear | M=80,N=(99,64),K=256 | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_stages_32x1_nt |
| 11293 | bprop | Decoder:PreNet | linear | M=80,N=256,K=(99,64) | splitKreduce_kernel |
Back propagation: Bi-directional LSTM
Kernels 11294 through 11402 correspond to back propagation through
the bi-directional LSTM layer. During back propagation, we have to
calculate $\partial H$, $\partial X$ (data gradients) and $\partial W$
(weight gradient).
The number of data gradients to calculate is equal to sequence length * 2 because we have a bi-directional LSTM. The 28 triplets of
LSTM_elementWise_bp1, cutlass::Kernel, splitKreduce_kernel most
likely correspond to this operation.
It appears contributions to $\partial W$ are calculated every 4 steps in
each direction. The number of (batched) GEMM kernels required to calculate
the weight gradients is equal to $\left \lceil \frac{\text{sequence
length}}{4} \right \rceil \times 2 = 8. $The kernels turing_*_nn most
likely correspond to this operation.
There are 6 additional GEMM kernels (volta|turing)_*_nt, which I am
unable to decipher.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 11294 | fprop | - | copy_ | na=na, | modern::unrolled_elementwise_kernel |
| 11295 | bprop | Encoder | _pad_packed_sequence | na=na, | modern::vectorized_elementwise_kernel |
| 11296 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | modern::vectorized_elementwise_kernel |
| 11297 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | modern::vectorized_elementwise_kernel |
| 11298 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11299 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11300 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11301 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11302 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11303 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11304 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11305 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11306 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11307 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11308 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11309 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11310 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11311 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11312 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11313 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11314 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11315 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11316 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11317 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11318 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11319 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11320 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11321 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11322 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | turing_fp16_s1688gemm_fp16_64x64_sliced1x4_ldg8_f2f_nn |
| 11323 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | turing_fp16_s1688gemm_fp16_64x64_sliced1x4_ldg8_f2f_nn |
| 11324 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11325 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11326 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11327 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11328 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11329 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11330 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11331 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11332 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11333 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11334 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11335 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11336 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11337 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11338 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11339 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11340 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11341 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11342 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11343 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11344 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11345 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11346 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11347 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11348 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | turing_fp16_s1688gemm_fp16_64x64_sliced1x4_ldg8_f2f_nn |
| 11349 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | turing_fp16_s1688gemm_fp16_64x64_sliced1x4_ldg8_f2f_nn |
| 11350 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11351 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11352 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11353 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11354 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11355 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11356 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11357 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11358 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11359 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11360 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11361 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11362 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11363 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11364 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11365 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11366 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11367 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11368 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11369 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11370 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11371 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11372 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11373 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11374 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | turing_fp16_s1688gemm_fp16_64x64_sliced1x4_ldg8_f2f_nn |
| 11375 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | turing_fp16_s1688gemm_fp16_64x64_sliced1x4_ldg8_f2f_nn |
| 11376 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11377 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11378 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11379 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11380 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11381 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11382 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11383 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11384 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11385 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | LSTM_elementWise_bp1 |
| 11386 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | cutlass::Kernel |
| 11387 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11388 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | turing_fp16_s1688gemm_fp16_256x64_ldg8_f2f_stages_32x1_nn |
| 11389 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11390 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | turing_fp16_s1688gemm_fp16_256x64_ldg8_f2f_stages_32x1_nn |
| 11391 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | splitKreduce_kernel |
| 11392 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | RNN_bidirectional_accum_bp1_1 |
| 11393 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | modern::vectorized_elementwise_kernel |
| 11394 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | GENERIC_elementWise_bp2 |
| 11395 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | GENERIC_elementWise_bp2 |
| 11396 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nt |
| 11397 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | turing_fp16_s1688gemm_fp16_64x128_sliced1x2_ldg8_f2f_nt |
| 11398 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | turing_fp16_s1688gemm_fp16_128x256_ldg8_f2f_stages_32x1_nt |
| 11399 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | volta_fp16_s884gemm_fp16_64x64_ldg8_f2f_nt |
| 11400 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | turing_fp16_s1688gemm_fp16_64x128_sliced1x2_ldg8_f2f_nt |
| 11401 | bprop | Encoder:LSTM | forward | T=[(896,512),(14,)] | turing_fp16_s1688gemm_fp16_128x256_ldg8_f2f_stages_32x1_nt |
| 11402 | bprop | Encoder | _pack_padded_sequence | na=na, | modern::vectorized_elementwise_kernel |
Back propagation: 3 Convolution Layers
Kernels 11403 through 11432 correspond to back propagation through the 3 convolution layers.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 11403 | bprop | Encoder:Conv_3 | relu | [64,512,14] | modern::unrolled_elementwise_kernel |
| 11404 | bprop | Encoder:Conv_3 | batch_norm | [64,512,14] | modern::vectorized_elementwise_kernel |
| 11405 | bprop | Encoder:Conv_3 | __add__ | [];[] | cudnn::bn_bw_1C11_singleread_fp16 |
| 11406 | fprop | - | na=na, | reduce_kernel | |
| 11407 | bprop | Encoder:Conv_3 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | cudnn::ops::scalePackedTensor_kernel |
| 11408 | bprop | Encoder:Conv_3 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | cudnn::detail::dgrad_alg1_engine |
| 11409 | bprop | Encoder:Conv_3 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 11410 | bprop | Encoder:Conv_3 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 11411 | bprop | Encoder:Conv_3 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | xmma_new::gemm::kernel |
| 11412 | bprop | Encoder:Conv_3 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | nhwcToNchwKernel |
| 11413 | bprop | Encoder:Conv_2 | relu | [64,512,14] | modern::vectorized_elementwise_kernel |
| 11414 | bprop | Encoder:Conv_2 | batch_norm | [64,512,14] | modern::vectorized_elementwise_kernel |
| 11415 | bprop | Encoder:Conv_2 | __add__ | [];[] | cudnn::bn_bw_1C11_singleread_fp16 |
| 11416 | fprop | - | na=na, | reduce_kernel | |
| 11417 | bprop | Encoder:Conv_2 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | cudnn::ops::scalePackedTensor_kernel |
| 11418 | bprop | Encoder:Conv_2 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | cudnn::detail::dgrad_alg1_engine |
| 11419 | bprop | Encoder:Conv_2 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 11420 | bprop | Encoder:Conv_2 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 11421 | bprop | Encoder:Conv_2 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | xmma_new::gemm::kernel |
| 11422 | bprop | Encoder:Conv_2 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | nhwcToNchwKernel |
| 11423 | bprop | Encoder:Conv_1 | relu | [64,512,14] | modern::vectorized_elementwise_kernel |
| 11424 | bprop | Encoder:Conv_1 | batch_norm | [64,512,14] | modern::vectorized_elementwise_kernel |
| 11425 | bprop | Encoder:Conv_1 | __add__ | [];[] | cudnn::bn_bw_1C11_singleread_fp16 |
| 11426 | fprop | - | na=na, | reduce_kernel | |
| 11427 | bprop | Encoder:Conv_1 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | cudnn::ops::scalePackedTensor_kernel |
| 11428 | bprop | Encoder:Conv_1 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | cudnn::detail::dgrad_alg1_engine |
| 11429 | bprop | Encoder:Conv_1 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 11430 | bprop | Encoder:Conv_1 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | nchwToNhwcKernel |
| 11431 | bprop | Encoder:Conv_1 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | xmma_new::gemm::kernel |
| 11432 | bprop | Encoder:Conv_1 | conv1d | N=64,C=512,H=1,W=14,K=512,P=1,Q=14,R=1,S=5,ph=0,pw=2 | nhwcToNchwKernel |
Back propagation: Character Embedding
Kernels 11433 through 11444 correspond to back propagation through the embedding layer.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 11433 | bprop | Embedding | embedding | [64,14];[148,512] | modern::unrolled_elementwise_kernel |
| 11434 | bprop | Embedding | embedding | [64,14];[148,512] | thrust::cuda_cub::core::_kernel_agent |
| 11435 | bprop | Embedding | embedding | [64,14];[148,512] | thrust::cuda_cub::core::_kernel_agent |
| 11436 | bprop | Embedding | embedding | [64,14];[148,512] | modern::vectorized_elementwise_kernel |
| 11437 | bprop | Embedding | embedding | [64,14];[148,512] | thrust::cuda_cub::core::_kernel_agent |
| 11438 | bprop | Embedding | embedding | [64,14];[148,512] | thrust::cuda_cub::core::_kernel_agent |
| 11439 | bprop | Embedding | embedding | [64,14];[148,512] | krn_partials_per_segment |
| 11440 | bprop | Embedding | embedding | [64,14];[148,512] | thrust::cuda_cub::core::_kernel_agent |
| 11441 | bprop | Embedding | embedding | [64,14];[148,512] | thrust::cuda_cub::core::_kernel_agent |
| 11442 | bprop | Embedding | embedding | [64,14];[148,512] | krn_partial_segment_offset |
| 11443 | bprop | Embedding | embedding | [64,14];[148,512] | compute_grad_weight |
| 11444 | bprop | Embedding | embedding | [64,14];[148,512] | sum_and_scatter |
Loss scaling
Kernels 11445-11448 most likely correspond to reverting the loss scaling of the gradients.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 11445 | fprop | - | zero_ | [1] | modern::vectorized_elementwise_kernel |
| 11446 | fprop | - | multi_tensor_scale | T=[(1,),(148,512),(512,512,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(1024,512),(1024,256),(1024,),(1024,),(1024,512),(1024,256),(1024,),(1024,),(256,80),(256,256),(4096,768),(4096,1024),(4096,),(4096,),(128,1024),(128,512),(1,128),(32,2,31),(128,32),(4096,1536),(4096,1024),(4096,),(4096,),(80,1536),(80,),(1,1536),(1,),(512,80,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(80,512,5),(80,),(148,512),(512,512,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(1024,512),(1024,256),(1024,),(1024,),(1024,512),(1024,256),(1024,),(1024,),(256,80),(256,256),(4096,768),(4096,1024),(4096,),(4096,),(128,1024),(128,512),(1,128),(32,2,31),(128,32),(4096,1536),(4096,1024),(4096,),(4096,),(80,1536),(80,),(1,1536),(1,),(512,80,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(80,512,5),(80,)] | multi_tensor_apply_kernel |
| 11447 | fprop | - | multi_tensor_scale | T=[(1,),(148,512),(512,512,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(1024,512),(1024,256),(1024,),(1024,),(1024,512),(1024,256),(1024,),(1024,),(256,80),(256,256),(4096,768),(4096,1024),(4096,),(4096,),(128,1024),(128,512),(1,128),(32,2,31),(128,32),(4096,1536),(4096,1024),(4096,),(4096,),(80,1536),(80,),(1,1536),(1,),(512,80,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(80,512,5),(80,),(148,512),(512,512,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(1024,512),(1024,256),(1024,),(1024,),(1024,512),(1024,256),(1024,),(1024,),(256,80),(256,256),(4096,768),(4096,1024),(4096,),(4096,),(128,1024),(128,512),(1,128),(32,2,31),(128,32),(4096,1536),(4096,1024),(4096,),(4096,),(80,1536),(80,),(1,1536),(1,),(512,80,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(80,512,5),(80,)] | multi_tensor_apply_kernel |
| 11448 | fprop | - | multi_tensor_axpby | T=[(1,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(80,),(80,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(80,),(80,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(512,),(80,),(80,)] | multi_tensor_apply_kernel |
Clip by L2 norm
The model has 60 parameters and kernels 11449 through 11508 correspnd to calculating the L2 norm. We show only 1 entry in the table below. In kernels 11509 and 11510, we stack the L2 norms and calculate the norm again. Kernels 11511-11514 do some checks and calculate the scaling factor. Kernels 11515 through 11574 scale the gradients. We show only 1 entry in the table below.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 11449 | fprop | - | norm | T=(148,512) | reduce_kernel |
| 11509 | fprop | - | stack | T=[],[] | CatArrayBatchedCopy |
| 11510 | fprop | - | norm | T=(60,) | reduce_kernel |
| 11511 | fprop | - | __add__ | [];[] | modern::vectorized_elementwise_kernel |
| 11512 | fprop | - | __rtruediv__ | [];[] | modern::vectorized_elementwise_kernel |
| 11513 | fprop | - | __rtruediv__ | [];[] | modern::vectorized_elementwise_kernel |
| 11514 | fprop | - | __lt__ | [];[] | modern::vectorized_elementwise_kernel |
| 11515 | fprop | - | mul_ | [148,512];[] | modern::unrolled_elementwise_kernel |
Adam optimizer
The last step is to apply the Adam optimizer on the model weights. The model has 60 parameters. Each call to the Adam optimizer invokes 9 kernels, for a total of 540 kernels (11575 through 12114). This is not an optimized implementation and one can use the fused Adam implementation from Nvidia Apex. The table below shows the kernels invoked for just 1 parameter update, the character embedding table.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 11575 | fprop | - | add | [148,512];[148,512] | modern::vectorized_elementwise_kernel |
| 11576 | fprop | - | mul_ | [148,512];[] | modern::vectorized_elementwise_kernel |
| 11577 | fprop | - | add_ | [148,512];[148,512] | modern::vectorized_elementwise_kernel |
| 11578 | fprop | - | mul_ | [148,512];[] | modern::vectorized_elementwise_kernel |
| 11579 | fprop | - | addcmul_ | [148,512];[148,512];[148,512] | modern::vectorized_elementwise_kernel |
| 11580 | fprop | - | sqrt | [148,512] | modern::vectorized_elementwise_kernel |
| 11581 | fprop | - | __truediv__ | [148,512];[] | modern::vectorized_elementwise_kernel |
| 11582 | fprop | - | add_ | [148,512];[] | modern::vectorized_elementwise_kernel |
| 11583 | fprop | - | addcdiv_ | [148,512];[148,512];[148,512] | modern::vectorized_elementwise_kernel |
Scaling
Kernels 12115 and 12116 appear to be doing some sort of scaling but am not sure why.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 12115 | fprop | - | multi_tensor_scale | T=[(1,),(148,512),(512,512,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(1024,512),(1024,256),(1024,),(1024,),(1024,512),(1024,256),(1024,),(1024,),(256,80),(256,256),(4096,768),(4096,1024),(4096,),(4096,),(128,1024),(128,512),(1,128),(32,2,31),(128,32),(4096,1536),(4096,1024),(4096,),(4096,),(80,1536),(80,),(1,1536),(1,),(512,80,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(80,512,5),(80,),(148,512),(512,512,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(1024,512),(1024,256),(1024,),(1024,),(1024,512),(1024,256),(1024,),(1024,),(256,80),(256,256),(4096,768),(4096,1024),(4096,),(4096,),(128,1024),(128,512),(1,128),(32,2,31),(128,32),(4096,1536),(4096,1024),(4096,),(4096,),(80,1536),(80,),(1,1536),(1,),(512,80,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(80,512,5),(80,)] | multi_tensor_apply_kernel |
| 12116 | fprop | - | multi_tensor_scale | T=[(1,),(148,512),(512,512,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(1024,512),(1024,256),(1024,),(1024,),(1024,512),(1024,256),(1024,),(1024,),(256,80),(256,256),(4096,768),(4096,1024),(4096,),(4096,),(128,1024),(128,512),(1,128),(32,2,31),(128,32),(4096,1536),(4096,1024),(4096,),(4096,),(80,1536),(80,),(1,1536),(1,),(512,80,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(80,512,5),(80,),(148,512),(512,512,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(1024,512),(1024,256),(1024,),(1024,),(1024,512),(1024,256),(1024,),(1024,),(256,80),(256,256),(4096,768),(4096,1024),(4096,),(4096,),(128,1024),(128,512),(1,128),(32,2,31),(128,32),(4096,1536),(4096,1024),(4096,),(4096,),(80,1536),(80,),(1,1536),(1,),(512,80,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(512,512,5),(512,),(80,512,5),(80,)] | multi_tensor_apply_kernel |