Neural Collaborative Filtering (NCF)
May 24, 2020
Neural Collaborative Filtering is a network for recommendation systems and was one of the benchmarks in the MLPerf 0.5 submission. It is a small network with about 10 layers, however, a single training step (forward and backward propagation) invokes about 200 GPU CUDA kernels (depending on the batch size). The best way to understand a DL network and GPU performance is to understand every single CUDA kernel i.e. which layer of the network invoked the kernel, with what arguments (tensor shapes and datatypes) and in which direction (forward propagation or backward propagation).
In this blog post, I will explain every kernel used in the training of
NCF. All the information in the tables below was obtained using NVidia's
PyTorch Profiler, PyProf, on a Turing T4 GPU. The information below
is only a subset of what is provided by PyProf. The code and instructions
for obtaining a detailed profile are here. Note that Volta
and Ampere GPUs will have slightly different kernel names e.g. volta_*
as opposed to turing_*.
Model Architecture
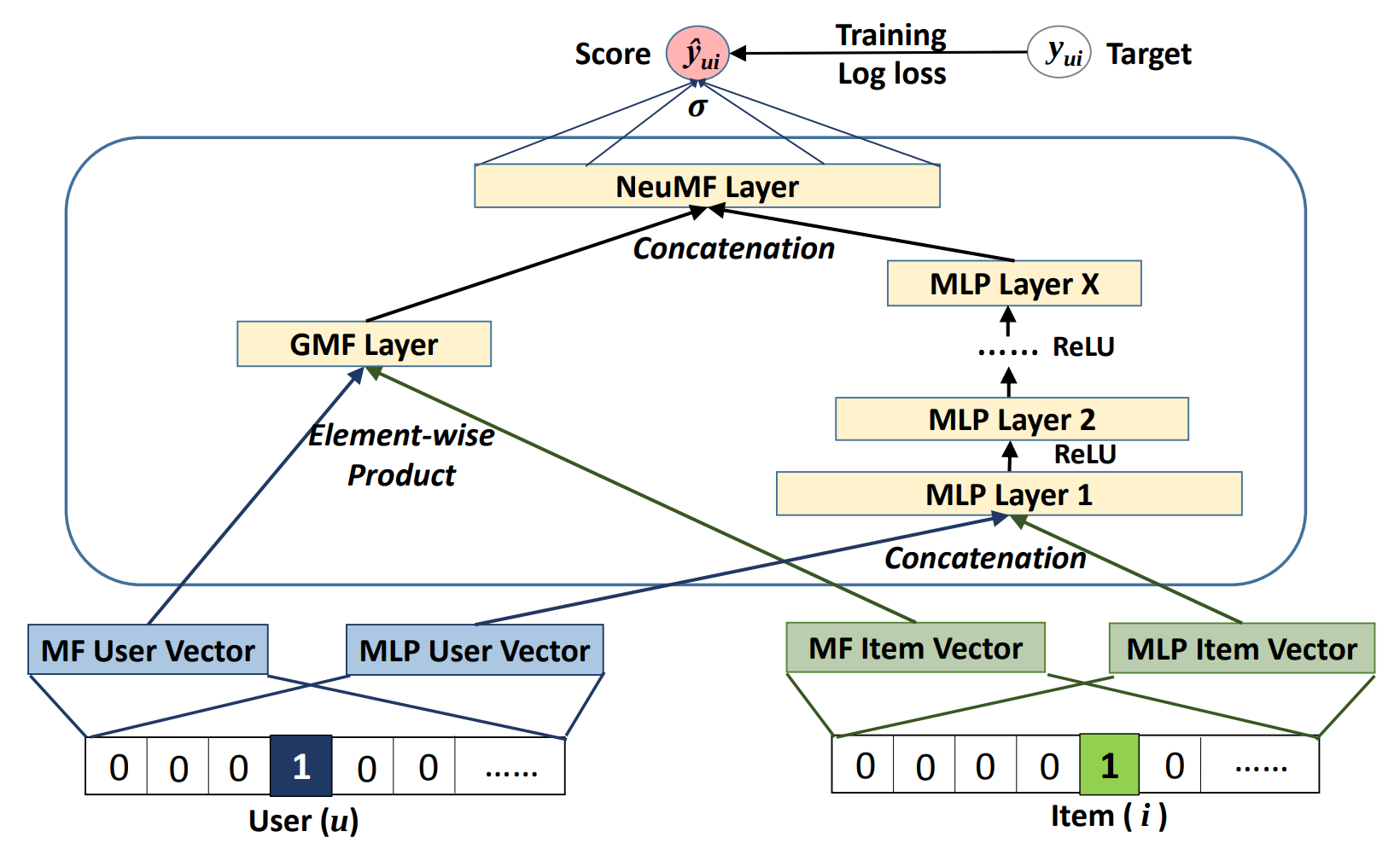
{kind=link}
Model Parameters
The parameters in the profiled code are
Users = 138493
Items = 26744
MF User Embedding = 64
MF Item Embedding = 64
MLP User Embedding = 128
MLP Item Embedding = 128
MLP Layers = [256, 128, 64]
Batch Size = 1048576GPU Kernels
The tables below show the GPU kernels invoked in 1 training step. For every GPU kernel we show the direction (fprop, bprop), name of the layer, name of the operation, and the input tensor shapes / matrix dimensions for the operation. PyProf provides a lot of additional information for every GPU kernel e.g. grid dimensions, block dimensions, silicon time, datatypes, flops, bytes, tensor core usage and so on.
Kernels 1 through 38 correspond to forward propagation. Kernels 1, 2, 4 and 5 correspond to the four embedding lookups. Kernel 3 corresponds to the element wise multiplication (Hadamard product). Kernel 6 corresponds to the concatenation before the MLP layers. Kernels 7 through 18 correspond to the 3 Linear layers. Kernel 19 corresponds to the concatenation before the NeuMF layer. Kernels 20, 21 correspond to the final NeuMF Linear layer. Kernel 22 corresponds to a cast operation from float16 to float32 before the loss layer.
| Idx | Direction | Layer | Op | Params | GPU Kernel |
|---|---|---|---|---|---|
| 1 | fprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | indexSelectLargeIndex |
| 2 | fprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | indexSelectLargeIndex |
| 3 | fprop | GMF | mul | T=[(1048576,64), (1048576,64)] | modern::elementwise_kernel |
| 4 | fprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | indexSelectLargeIndex |
| 5 | fprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | indexSelectLargeIndex |
| 6 | fprop | MLP_Concat | cat | T=[(1048576,128), (1048576,128)] | CatArrayBatchedCopy |
| 7 | fprop | MLP_0 | bias | M=256, N=1048576 | legacy::elementwise_kernel |
| 8 | fprop | MLP_0 | linear | M=256, N=1048576, K=256 | turing_s1688gemm_128x128_ldg8_f2f_tn |
| 9 | fprop | MLP_0 | relu | T=(1048576,256) | modern::elementwise_kernel |
| 10 | fprop | MLP_0:Dropout | dropout | T=(1048576,256) | fused_dropout_kernel |
| 11 | fprop | MLP_1 | bias | M=128, N=1048576 | legacy::elementwise_kernel |
| 12 | fprop | MLP_1 | linear | M=128, N=1048576, K=256 | turing_s1688gemm_128x128_ldg8_f2f_tn |
| 13 | fprop | MLP_1 | relu | T=(1048576,128) | modern::elementwise_kernel |
| 14 | fprop | MLP_1:Dropout | dropout | T=(1048576,128) | fused_dropout_kernel |
| 15 | fprop | MLP_2 | bias | M=64, N=1048576 | legacy::elementwise_kernel |
| 16 | fprop | MLP_2 | linear | M=64, N=1048576, K=128 | turing_s884gemm_64x128_ldg8_f2f_tn |
| 17 | fprop | MLP_2 | relu | T=(1048576,64) | modern::elementwise_kernel |
| 18 | fprop | MLP_2:Dropout | dropout | T=(1048576,64) | fused_dropout_kernel |
| 19 | fprop | NeuMF_Concat | cat | T=[(1048576,64), (1048576,64)] | CatArrayBatchedCopy |
| 20 | fprop | NeuMF_MLP | bias | M=1, N=1048576 | legacy::elementwise_kernel |
| 21 | fprop | NeuMF_MLP | linear | M=1, N=1048576, K=128 | gemv2T_kernel_val |
| 22 | fprop | - | to | T=(1048576,1) | legacy::elementwise_kernel |
Kernels 23 through 36 correspond to the Binary Cross Entropy Loss calculation. Kernel 37 calculates the average loss. Kernel 38 corresponds to the static/dynamic loss scaling i.e. multiplication by a scalar.
| Idx | Direction | Layer | Op | Params | GPU Kernel |
|---|---|---|---|---|---|
| 23 | fprop | Loss | bce_with_logits | T=[(1048576,1), (1048576,1)] | modern::elementwise_kernel |
| 24 | fprop | Loss | bce_with_logits | T=[(1048576,1), (1048576,1)] | kernelPointwiseApply1 |
| 25 | fprop | Loss | bce_with_logits | T=[(1048576,1), (1048576,1)] | modern::elementwise_kernel |
| 26 | fprop | Loss | bce_with_logits | T=[(1048576,1), (1048576,1)] | modern::elementwise_kernel |
| 27 | fprop | Loss | bce_with_logits | T=[(1048576,1), (1048576,1)] | modern::elementwise_kernel |
| 28 | fprop | Loss | bce_with_logits | T=[(1048576,1), (1048576,1)] | modern::elementwise_kernel |
| 29 | fprop | Loss | bce_with_logits | T=[(1048576,1), (1048576,1)] | modern::elementwise_kernel |
| 30 | fprop | Loss | bce_with_logits | T=[(1048576,1), (1048576,1)] | kernelPointwiseApply1 |
| 31 | fprop | Loss | bce_with_logits | T=[(1048576,1), (1048576,1)] | modern::elementwise_kernel |
| 32 | fprop | Loss | bce_with_logits | T=[(1048576,1), (1048576,1)] | modern::elementwise_kernel |
| 33 | fprop | Loss | bce_with_logits | T=[(1048576,1), (1048576,1)] | kernelPointwiseApply1 |
| 34 | fprop | Loss | bce_with_logits | T=[(1048576,1), (1048576,1)] | modern::elementwise_kernel |
| 35 | fprop | Loss | bce_with_logits | T=[(1048576,1), (1048576,1)] | modern::elementwise_kernel |
| 36 | fprop | Loss | bce_with_logits | T=[(1048576,1), (1048576,1)] | modern::elementwise_kernel |
| 37 | fprop | Mean | mean | T=(1048576) | reduce_kernel |
| 38 | fprop | - | mul | T=[(1)] | legacy::elementwise_kernel |
The following kernels are invoked during back propagation. Kernels 42 through 44 correspond to the Loss layer (in float32). Kernel 45 converts the gradient from float32 to float16. Kernels 46 through 48 calculate the data gradient and weight gradient through the NeuMF Linear layer. Kernel 49 calculates the bias gradient. Kernels 50 through 67 calculate the gradient through the dropout layer, ReLU layer, data gradient, weight gradient, and bias gradient through the three Linear layers.
| Idx | Direction | Layer | Op | Params | GPU Kernel |
|---|---|---|---|---|---|
| 39 | bprop | - | backward | legacy::elementwise_kernel | |
| 40 | bprop | - | mul | T=[(1)] | legacy::elementwise_kernel |
| 41 | bprop | - | div | na=na | legacy::elementwise_kernel |
| 42 | bprop | Loss | bce_with_logits | T=[(1048576,1), (1048576,1)] | modern::elementwise_kernel |
| 43 | bprop | Loss | bce_with_logits | T=[(1048576,1), (1048576,1)] | modern::elementwise_kernel |
| 44 | bprop | Loss | bce_with_logits | T=[(1048576,1), (1048576,1)] | modern::elementwise_kernel |
| 45 | bprop | - | to | na=na | legacy::elementwise_kernel |
| 46 | bprop | NeuMF_MLP | linear | M=128, N=1048576, K=1 | volta_sgemm_128x64_nn |
| 47 | bprop | NeuMF_MLP | linear | M=128, N=1, K=1048576 | gemv2N_kernel |
| 48 | bprop | NeuMF_MLP | linear | X=(1048576,128), W=(1,128) | splitKreduce_kernel |
| 49 | bprop | - | sum | na=na | reduce_kernel |
| 50 | bprop | MLP_2:Dropout | dropout | T=(1048576,64) | kernelPointwiseApply3 |
| 51 | bprop | MLP_2 | relu | T=(1048576,64) | modern::elementwise_kernel |
| 52 | bprop | MLP_2 | linear | M=128, N=1048576, K=64 | turing_s1688gemm_128x128_ldg8_f2f_nn |
| 53 | bprop | MLP_2 | linear | M=128, N=64, K=1048576 | turing_s1688gemm_128x128_ldg8_f2f_nt |
| 54 | bprop | MLP_2 | linear | X=(1048576,128), W=(64,128) | splitKreduce_kernel |
| 55 | bprop | - | sum | na=na | reduce_kernel |
| 56 | bprop | MLP_1:Dropout | dropout | T=(1048576,128) | kernelPointwiseApply3 |
| 57 | bprop | MLP_1 | relu | T=(1048576,128) | modern::elementwise_kernel |
| 58 | bprop | MLP_1 | linear | M=256, N=1048576, K=128 | turing_s1688gemm_128x128_ldg8_f2f_nn |
| 59 | bprop | MLP_1 | linear | M=256, N=128, K=1048576 | turing_s1688gemm_256x128_ldg8_f2f_nt |
| 60 | bprop | MLP_1 | linear | X=(1048576,256), W=(128,256) | splitKreduce_kernel |
| 61 | bprop | - | sum | na=na | reduce_kernel |
| 62 | bprop | MLP_0:Dropout | dropout | T=(1048576,256) | kernelPointwiseApply3 |
| 63 | bprop | MLP_0 | relu | T=(1048576,256) | modern::elementwise_kernel |
| 64 | bprop | MLP_0 | linear | M=256, N=1048576, K=256 | turing_s1688gemm_128x128_ldg8_f2f_nn |
| 65 | bprop | MLP_0 | linear | M=256, N=256, K=1048576 | turing_s1688gemm_256x128_ldg8_f2f_nt |
| 66 | bprop | MLP_0 | linear | X=(1048576,256), W=(256,256) | splitKreduce_kernel |
| 67 | bprop | - | sum | na=na | reduce_kernel |
Back propagation through the Embedding layers invoke a lot of Thrust and CUB kernels. Kernels 68 through 97 correspond to the MLP Item Embedding layer.
| Idx | Direction | Layer | Op | Params | GPU Kernel |
|---|---|---|---|---|---|
| 68 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | legacy::elementwise_kernel |
| 69 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 70 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 71 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 72 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 73 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 74 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 75 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 76 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 77 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 78 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 79 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 80 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 81 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 82 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 83 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 84 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 85 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 86 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 87 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 88 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 89 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | modern::elementwise_kernel |
| 90 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 91 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 92 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | krn_partials_per_segment |
| 93 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 94 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | thrust::cuda_cub::core::_kernel_agent |
| 95 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | krn_partial_segment_offset |
| 96 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | compute_grad_weight |
| 97 | bprop | MLP_Item_Embedding | embedding | I=(1048576), E=(26744,128) | sum_and_scatter |
Kernels 98 through 127 correspond to the MLP User Embedding layer.
| Idx | Direction | Layer | Op | Params | GPU Kernel |
|---|---|---|---|---|---|
| 98 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | legacy::elementwise_kernel |
| 99 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 100 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 101 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 102 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 103 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 104 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 105 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 106 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 107 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 108 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 109 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 110 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 111 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 112 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 113 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 114 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 115 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 116 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 117 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 118 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 119 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | modern::elementwise_kernel |
| 120 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 121 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 122 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | krn_partials_per_segment |
| 123 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 124 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | thrust::cuda_cub::core::_kernel_agent |
| 125 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | krn_partial_segment_offset |
| 126 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | compute_grad_weight |
| 127 | bprop | MLP_User_Embedding | embedding | I=(1048576), E=(138493,128) | sum_and_scatter |
Kernels 128, 129 correspond to the element wise multiplication.
| Idx | Direction | Layer | Op | Params | GPU Kernel |
|---|---|---|---|---|---|
| 128 | bprop | GMF | mul | T=[(1048576,64), (1048576,64)] | legacy::elementwise_kernel |
| 129 | bprop | GMF | mul | T=[(1048576,64), (1048576,64)] | legacy::elementwise_kernel |
Kernels 130 through 158 correspond to the MF Item Embedding layer.
| Idx | Direction | Layer | Op | Params | GPU Kernel |
|---|---|---|---|---|---|
| 130 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 131 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 132 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 133 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 134 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 135 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 136 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 137 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 138 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 139 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 140 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 141 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 142 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 143 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 144 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 145 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 146 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 147 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 148 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 149 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 150 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | modern::elementwise_kernel |
| 151 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 152 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 153 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | krn_partials_per_segment |
| 154 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 155 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | thrust::cuda_cub::core::_kernel_agent |
| 156 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | krn_partial_segment_offset |
| 157 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | compute_grad_weight |
| 158 | bprop | MF_Item_Embedding | embedding | I=(1048576), E=(26744,64) | sum_and_scatter |
Kernels 159 through 187 correspond to the MF User Embedding layer.
| Idx | Direction | Layer | Op | Params | GPU Kernel |
|---|---|---|---|---|---|
| 159 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 160 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 161 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 162 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 163 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 164 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 165 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 166 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 167 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 168 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 169 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 170 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 171 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 172 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 173 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 174 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 175 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 176 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 177 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 178 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 179 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | modern::elementwise_kernel |
| 180 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 181 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 182 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | krn_partials_per_segment |
| 183 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 184 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | thrust::cuda_cub::core::_kernel_agent |
| 185 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | krn_partial_segment_offset |
| 186 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | compute_grad_weight |
| 187 | bprop | MF_User_Embedding | embedding | I=(1048576), E=(138493,64) | sum_and_scatter |
At the end of back propagation, we have all the weight gradients. Kernels 188 through 194 correspond to reversing the loss scaling and applying the Adam optimizer on all the weights and biases.
| Idx | Direction | Layer | Op | Params | GPU Kernel |
|---|---|---|---|---|---|
| 188 | fprop | - | zero | T=[(1)] | modern::elementwise_kernel |
| 189 | fprop | - | multi_tensor_scale | T=[(1), (138493,64), (26744,64), (138493,128), (26744,128), (256,256), (256), (128,256), (128), (64,128), (64), (1,128), (1), (138493,64), (26744,64), (138493,128), (26744,128), (256,256), (256), (128,256), (128), (64,128), (64), (1,128), (1)] | multi_tensor_apply_kernel |
| 190 | fprop | - | multi_tensor_scale | T=[(1), (138493,64), (26744,64), (138493,128), (26744,128), (256,256), (256), (128,256), (128), (64,128), (64), (1,128), (1), (138493,64), (26744,64), (138493,128), (26744,128), (256,256), (256), (128,256), (128), (64,128), (64), (1,128), (1)] | multi_tensor_apply_kernel |
| 191 | fprop | Adam | na=na | multi_tensor_apply_kernel | |
| 192 | fprop | Adam | na=na | multi_tensor_apply_kernel | |
| 193 | fprop | Adam | multi_tensor_scale | T=[(1), (138493,64), (26744,64), (138493,128), (26744,128), (256,256), (256), (128,256), (128), (64,128), (64), (1,128), (1), (138493,64), (26744,64), (138493,128), (26744,128), (256,256), (256), (128,256), (128), (64,128), (64), (1,128), (1)] | multi_tensor_apply_kernel |
| 194 | fprop | Adam | multi_tensor_scale | T=[(1), (138493,64), (26744,64), (138493,128), (26744,128), (256,256), (256), (128,256), (128), (64,128), (64), (1,128), (1), (138493,64), (26744,64), (138493,128), (26744,128), (256,256), (256), (128,256), (128), (64,128), (64), (1,128), (1)] | multi_tensor_apply_kernel |