Deep Convolutional Generative Adversarial Network (DCGAN)
September 26, 2020
Generative Adversarial Networks GANs are a type of generative models. The objective of generative models is to learn the training data distribution, so as to enable generation of new data, through sampling from the same distribution. The other popular types of generative models are Variational Auto Encoders VAEs and Normalizing Flow based models e.g. NICE, Glow. Deep Convolutional Generative Adversarial Network DCGAN, as the name suggests is a GAN. The distinguishing feature is that it uses convolutions in the discriminator and transposed convolutions in the generator.
GANs have a very unique training procedure. In the first phase, we train the discriminator and in the second phase, we train the generator. While training DCGAN on MNIST, a single training step (forward and backward propagation) invokes about 500 GPU CUDA kernels. The best way to understand the GAN training procedure and GPU performance is to understand every CUDA kernel i.e. which layer of the network invoked the kernel, with what arguments (tensor shapes and datatypes) and in which direction (forward propagation or backward propagation).
In this post, we will categorize every kernel used in the training
of DCGAN. All the information in the tables below was obtaining
using Nvidia's PyTorch Profiler, PyProf, on a Turing T4 GPU. The
information below is only a subset of what is provided by PyProf. The code
and instructions for obtaining a detailed profile are here. Note
that different GPUs will have slightly different kernel names e.g.
volta_* as opposed to turing_*.
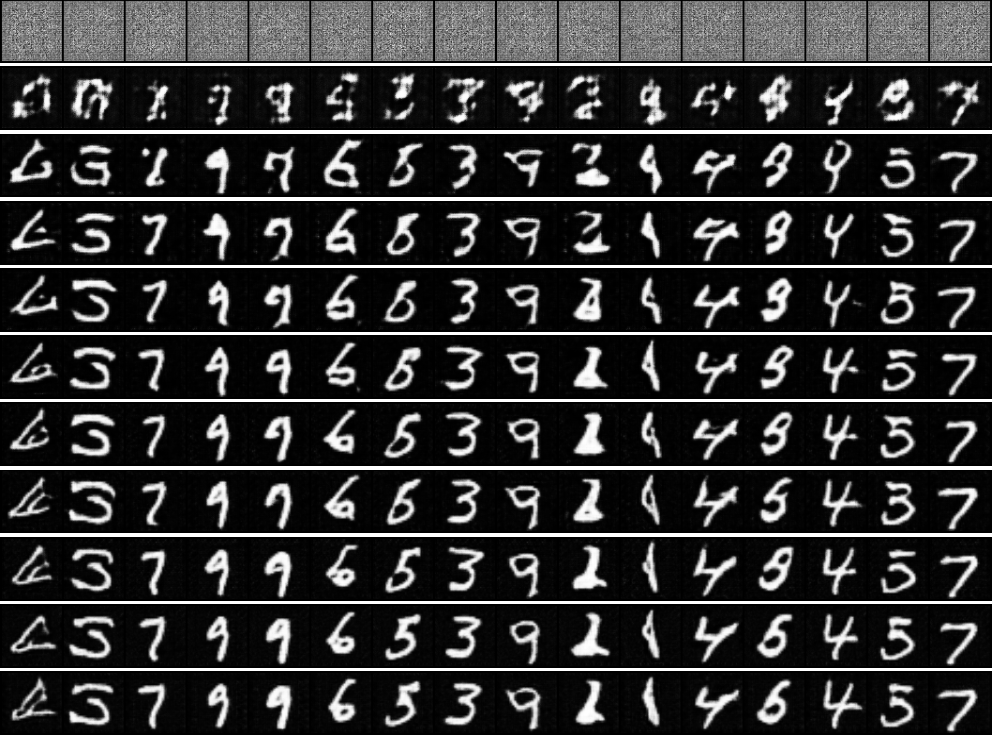
The code for DCGAN was obtained from PyTorch DCGAN Tutorial and modified to use MNIST. The image below shows the output of the generator on a fixed noise at the beginning and at the end of epochs 1 through 10.
Model Parameters
The parameters in the profiled code are as follows.
# Size of training images.
image_size = 64
# Channels in the training images.
# 3 for color images, 1 for MNIST.
nc = 1
# Size of latent vector (i.e. size of generator input).
nz = 100
# Size of feature maps in generator.
ngf = 64
# Size of feature maps in discriminator.
ndf = 64
batch_size = 128GPU Kernels
The tables below show the GPU kernels invoked in 1 training step. For every GPU kernel we show the direction (fprop, bprop), name of the layer, name of the operation, and the input tensor shapes / matrix dimensions for the operation. PyProf provides a lot of additional information for every GPU kernel e.g. grid dimensions, block dimensions, silicon time, datatypes, flops, bytes, tensor core usage and so on.
GAN training consists of two parts. Part 1, where we train the discriminator and part 2, where we train the generator.
Part 1: Train the Discriminator
Zero out the discriminator gradients.
At the beginning of part 1, we zero out the gradients of the discriminator.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 1 | fprop | Part1:D_Gradient | zero_ | [64,1,4,4] | modern::elementwise_kernel |
| 2 | fprop | Part1:D_Gradient | zero_ | [128,64,4,4] | modern::elementwise_kernel |
| 3 | fprop | Part1:D_Gradient | zero_ | [128] | modern::elementwise_kernel |
| 4 | fprop | Part1:D_Gradient | zero_ | [128] | modern::elementwise_kernel |
| 5 | fprop | Part1:D_Gradient | zero_ | [256,128,4,4] | modern::elementwise_kernel |
| 6 | fprop | Part1:D_Gradient | zero_ | [256] | modern::elementwise_kernel |
| 7 | fprop | Part1:D_Gradient | zero_ | [256] | modern::elementwise_kernel |
| 8 | fprop | Part1:D_Gradient | zero_ | [512,256,4,4] | modern::elementwise_kernel |
| 9 | fprop | Part1:D_Gradient | zero_ | [512] | modern::elementwise_kernel |
| 10 | fprop | Part1:D_Gradient | zero_ | [512] | modern::elementwise_kernel |
| 11 | fprop | Part1:D_Gradient | zero_ | [1,512,4,4] | modern::elementwise_kernel |
Discriminator: Forward propagation on real images from the dataset.
We pick batch_size i.e. 128 images from the MNIST dataset and pass
them through the discriminator. The target label for these images is set
to 1 (kernel 12). The discriminator consists of 5 convolution layers.
Kernels 13-15 correspond to the first convolution and activation. The
input shape (N,C,H,W) is (128,1,64,64), the number of filters K
is 64, the kernel size (R,S) is (4,4), the padding (ph,pw) is
(1,1) and the horizontal and vertical stride (U,V) is (2,2). The
output shape (N,K,P,Q) is (128,64,32,32).
Kernels 16-20 correspond to the second convolution, batch norm and
activation. The output shape is (128,128,16,16).
Kernels 21-25 correspond to the third convolution, batch norm and
activation. The output shape is (128,256,8,8).
Kernels 26-30 correspond to the fourth convolution, batch norm and
activation. The output shape is (128,512,4,4).
Kernels 31-33 correspond to the fifth convolution and activation. Note
that K=1, therefore, the output shape is (128,1,1,1).
Kernels 34-35 calculate the loss with respect to misclassification of
real images from the dataset.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 12 | fprop | Part1 | full | [128] | modern::elementwise_kernel |
| 13 | fprop | Part1:Real:D:Conv1 | conv2d | N=128,C=1,H=64,W=64,K=64,P=32,Q=32,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeOffsetsKernel |
| 14 | fprop | Part1:Real:D:Conv1 | conv2d | N=128,C=1,H=64,W=64,K=64,P=32,Q=32,R=4,S=4,ph=1,pw=1,U=2,V=2 | volta_scudnn_128x64_relu_small_nn_v1 |
| 15 | fprop | Part1:Real:D:LRelu1 | leaky_relu | [128,64,32,32] | modern::elementwise_kernel |
| 16 | fprop | Part1:Real:D:Conv2 | conv2d | N=128,C=64,H=32,W=32,K=128,P=16,Q=16,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeOffsetsKernel |
| 17 | fprop | Part1:Real:D:Conv2 | conv2d | N=128,C=64,H=32,W=32,K=128,P=16,Q=16,R=4,S=4,ph=1,pw=1,U=2,V=2 | volta_scudnn_128x128_relu_small_nn_v1 |
| 18 | fprop | Part1:Real:D:BN2 | __add__ | [];[] | legacy::elementwise_kernel |
| 19 | fprop | Part1:Real:D:BN2 | batch_norm | [128,128,16,16] | cudnn::detail::bn_fw_tr_1C11_kernel_NCHW |
| 20 | fprop | Part1:Real:D:LRelu2 | leaky_relu | [128,128,16,16] | modern::elementwise_kernel |
| 21 | fprop | Part1:Real:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeOffsetsKernel |
| 22 | fprop | Part1:Real:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | volta_scudnn_128x128_relu_small_nn_v1 |
| 23 | fprop | Part1:Real:D:BN3 | __add__ | [];[] | legacy::elementwise_kernel |
| 24 | fprop | Part1:Real:D:BN3 | batch_norm | [128,256,8,8] | cudnn::detail::bn_fw_tr_1C11_kernel_NCHW |
| 25 | fprop | Part1:Real:D:LRelu3 | leaky_relu | [128,256,8,8] | modern::elementwise_kernel |
| 26 | fprop | Part1:Real:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeOffsetsKernel |
| 27 | fprop | Part1:Real:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | volta_scudnn_128x64_relu_small_nn_v1 |
| 28 | fprop | Part1:Real:D:BN4 | __add__ | [];[] | legacy::elementwise_kernel |
| 29 | fprop | Part1:Real:D:BN4 | batch_norm | [128,512,4,4] | cudnn::detail::bn_fw_tr_1C11_singleread |
| 30 | fprop | Part1:Real:D:LRelu4 | leaky_relu | [128,512,4,4] | modern::elementwise_kernel |
| 31 | fprop | Part1:Real:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | cudnn::gemm::computeOffsetsKernel |
| 32 | fprop | Part1:Real:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | volta_scudnn_128x32_relu_interior_nn_v1 |
| 33 | fprop | Part1:Real:D:Sigmoid | sigmoid | [128,1,1,1] | modern::elementwise_kernel |
| 34 | fprop | Part1:Real:Loss | binary_cross_entropy | [128,128] | kernelPointwiseApply3 |
| 35 | fprop | Part1:Real:Loss | binary_cross_entropy | [128,128] | reduce_kernel |
Discriminator: Backward propagation (real images).
We now perform back propagation through the discriminator and calculate
the gradients.
Kernels 37-38 correspond to bprop through the loss layer.
Kernels 39-46 correspond to bprop (data gradient and weight gradient) through the fifth convolution layer.
Kernels 48,49,52-57 correspond to bprop through the fourth convolution layer.
Kernels 59,60,63-70 correspond to bprop through the third convolution layer.
Kernels 72,73,76-78 correspond to bprop through the second convolution layer.
Kernels 80,81 correspond to bprop through the first convolution layer.
Note that the first convolution layer requires only a weight gradient and
not a data gradient. Kernels with the op add_, most likely correspond
to gradient accumulation i.e. adding the gradients to the previously
zeroed out gradient tensors. Kernel 83 calculates the average loss
(for reporting).
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 36 | fprop | Part1:Real | backward | legacy::elementwise_kernel | |
| 37 | bprop | Part1:Real:Loss | binary_cross_entropy | [128,128] | kernelPointwiseApply4 |
| 38 | bprop | Part1:Real:Loss | binary_cross_entropy | [128,128] | modern::elementwise_kernel |
| 39 | bprop | Part1:Real:D:Sigmoid | sigmoid | [128,1,1,1] | modern::elementwise_kernel |
| 40 | bprop | Part1:Real:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | cudnn::gemm::computeOffsetsKernel |
| 41 | bprop | Part1:Real:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | cudnn::gemm::computeBOffsetsKernel |
| 42 | bprop | Part1:Real:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | volta_scudnn_128x128_stridedB_small_nn_v1 |
| 43 | bprop | Part1:Real:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | cudnn::gemm::computeWgradSplitKOffsetsKernel |
| 44 | bprop | Part1:Real:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | scalePackedTensor_kernel |
| 45 | bprop | Part1:Real:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | cudnn::gemm::computeWgradBOffsetsKernel |
| 46 | bprop | Part1:Real:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | volta_scudnn_128x64_stridedB_splitK_interior_nn_v1 |
| 47 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 48 | bprop | Part1:Real:D:LRelu4 | leaky_relu | [128,512,4,4] | modern::elementwise_kernel |
| 49 | bprop | Part1:Real:D:BN4 | batch_norm | [128,512,4,4] | cudnn::detail::bn_bw_1C11_singleread |
| 50 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 51 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 52 | bprop | Part1:Real:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | scalePackedTensor_kernel |
| 53 | bprop | Part1:Real:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::detail::dgrad2d_alg1_1 |
| 54 | bprop | Part1:Real:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeWgradSplitKOffsetsKernel |
| 55 | bprop | Part1:Real:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | scalePackedTensor_kernel |
| 56 | bprop | Part1:Real:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeWgradBOffsetsKernel |
| 57 | bprop | Part1:Real:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | volta_scudnn_128x128_stridedB_splitK_small_nn_v1 |
| 58 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 59 | bprop | Part1:Real:D:LRelu3 | leaky_relu | [128,256,8,8] | modern::elementwise_kernel |
| 60 | bprop | Part1:Real:D:BN3 | batch_norm | [128,256,8,8] | cudnn::detail::bn_bw_1C11_kernel_new |
| 61 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 62 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 63 | bprop | Part1:Real:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | fft2d_r2c_32x32 |
| 64 | bprop | Part1:Real:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | fft2d_r2c_32x32 |
| 65 | bprop | Part1:Real:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | volta_gcgemm_32x32_nt |
| 66 | bprop | Part1:Real:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | fft2d_c2r_32x32 |
| 67 | bprop | Part1:Real:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeWgradSplitKOffsetsKernel |
| 68 | bprop | Part1:Real:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | scalePackedTensor_kernel |
| 69 | bprop | Part1:Real:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeWgradBOffsetsKernel |
| 70 | bprop | Part1:Real:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | volta_scudnn_128x128_stridedB_splitK_small_nn_v1 |
| 71 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 72 | bprop | Part1:Real:D:LRelu2 | leaky_relu | [128,128,16,16] | modern::elementwise_kernel |
| 73 | bprop | Part1:Real:D:BN2 | batch_norm | [128,128,16,16] | cudnn::detail::bn_bw_1C11_kernel_new |
| 74 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 75 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 76 | bprop | Part1:Real:D:Conv2 | conv2d | N=128,C=64,H=32,W=32,K=128,P=16,Q=16,R=4,S=4,ph=1,pw=1,U=2,V=2 | scalePackedTensor_kernel |
| 77 | bprop | Part1:Real:D:Conv2 | conv2d | N=128,C=64,H=32,W=32,K=128,P=16,Q=16,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::detail::dgrad2d_alg1_1 |
| 78 | bprop | Part1:Real:D:Conv2 | conv2d | N=128,C=64,H=32,W=32,K=128,P=16,Q=16,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::detail::wgrad_alg0_engine |
| 79 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 80 | bprop | Part1:Real:D:LRelu1 | leaky_relu | [128,64,32,32] | modern::elementwise_kernel |
| 81 | bprop | Part1:Real:D:Conv1 | conv2d | N=128,C=1,H=64,W=64,K=64,P=32,Q=32,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::detail::wgrad_alg0_engine |
| 82 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 83 | fprop | Part1:Real | mean | [128] | reduce_kernel |
Generator.
We now create batch_size i.e. 128 fake images using the generator.
The generator consists of 5 transposed convolutions which progressively
increase the image size from [nz,1,1] to [nc,ngf,ngf] i.e. from
[100,1,1] to [1,64,64].
Kernel 84 creates a random tensor of shape [batch_size, nz].
Kernels 85-90 correspond to the first transposed convolution, batch norm and activation. The output shape is [128,512,4,4].
Kernels 91-95 correspond to the second transposed convolution, batch norm and activation. The output shape is [128,256,8,8].
Kernels 96-102 correspond to the third transposed convolution, batch norm and activation. The output shape is [128,128,16,16].
Kernels 103-107 correspond to the fourth transposed convolution, batch norm and activation. The output shape is [128,64,32,32].
Kernels 108-110 correspond to the fifth transposed convolution and activation. The output shape is [128,1,64,64].
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 84 | fprop | Part1:Fake | randn | distribution_elementwise_grid_stride_kernel | |
| 85 | fprop | Part1:Fake:G:ConvT1 | conv_transpose2d | T=[(128,100,1,1),(100,512,4,4)] | cudnn::gemm::computeOffsetsKernel |
| 86 | fprop | Part1:Fake:G:ConvT1 | conv_transpose2d | T=[(128,100,1,1),(100,512,4,4)] | cudnn::gemm::computeBOffsetsKernel |
| 87 | fprop | Part1:Fake:G:ConvT1 | conv_transpose2d | T=[(128,100,1,1),(100,512,4,4)] | volta_scudnn_128x64_stridedB_small_nn_v1 |
| 88 | fprop | Part1:Fake:G:BN1 | __add__ | [];[] | legacy::elementwise_kernel |
| 89 | fprop | Part1:Fake:G:BN1 | batch_norm | [128,512,4,4] | cudnn::detail::bn_fw_tr_1C11_singleread |
| 90 | fprop | Part1:Fake:G:Relu1 | relu | [128,512,4,4] | modern::elementwise_kernel |
| 91 | fprop | Part1:Fake:G:ConvT2 | conv_transpose2d | T=[(128,512,4,4),(512,256,4,4)] | scalePackedTensor_kernel |
| 92 | fprop | Part1:Fake:G:ConvT2 | conv_transpose2d | T=[(128,512,4,4),(512,256,4,4)] | cudnn::detail::dgrad2d_alg1_1 |
| 93 | fprop | Part1:Fake:G:BN2 | __add__ | [];[] | legacy::elementwise_kernel |
| 94 | fprop | Part1:Fake:G:BN2 | batch_norm | [128,256,8,8] | cudnn::detail::bn_fw_tr_1C11_kernel_NCHW |
| 95 | fprop | Part1:Fake:G:Relu2 | relu | [128,256,8,8] | modern::elementwise_kernel |
| 96 | fprop | Part1:Fake:G:ConvT3 | conv_transpose2d | T=[(128,256,8,8),(256,128,4,4)] | fft2d_r2c_32x32 |
| 97 | fprop | Part1:Fake:G:ConvT3 | conv_transpose2d | T=[(128,256,8,8),(256,128,4,4)] | fft2d_r2c_32x32 |
| 98 | fprop | Part1:Fake:G:ConvT3 | conv_transpose2d | T=[(128,256,8,8),(256,128,4,4)] | volta_gcgemm_32x32_nt |
| 99 | fprop | Part1:Fake:G:ConvT3 | conv_transpose2d | T=[(128,256,8,8),(256,128,4,4)] | fft2d_c2r_32x32 |
| 100 | fprop | Part1:Fake:G:BN3 | __add__ | [];[] | legacy::elementwise_kernel |
| 101 | fprop | Part1:Fake:G:BN3 | batch_norm | [128,128,16,16] | cudnn::detail::bn_fw_tr_1C11_kernel_NCHW |
| 102 | fprop | Part1:Fake:G:Relu3 | relu | [128,128,16,16] | modern::elementwise_kernel |
| 103 | fprop | Part1:Fake:G:ConvT4 | conv_transpose2d | T=[(128,128,16,16),(128,64,4,4)] | scalePackedTensor_kernel |
| 104 | fprop | Part1:Fake:G:ConvT4 | conv_transpose2d | T=[(128,128,16,16),(128,64,4,4)] | cudnn::detail::dgrad2d_alg1_1 |
| 105 | fprop | Part1:Fake:G:BN4 | __add__ | [];[] | legacy::elementwise_kernel |
| 106 | fprop | Part1:Fake:G:BN4 | batch_norm | [128,64,32,32] | cudnn::detail::bn_fw_tr_1C11_kernel_NCHW |
| 107 | fprop | Part1:Fake:G:Relu4 | relu | [128,64,32,32] | modern::elementwise_kernel |
| 108 | fprop | Part1:Fake:G:ConvT5 | conv_transpose2d | T=[(128,64,32,32),(64,1,4,4)] | scalePackedTensor_kernel |
| 109 | fprop | Part1:Fake:G:ConvT5 | conv_transpose2d | T=[(128,64,32,32),(64,1,4,4)] | cudnn::detail::dgrad_engine |
| 110 | fprop | Part1:Fake:G:Tanh | tanh | [128,1,64,64] | kernelPointwiseApply2 |
Discriminator: Forward propagation on fake images from the generator.
The fake images from the generator are now fed to the discriminator. The target label for these images is set to 0 (kernel 111). Kernels 112 through 134 are the same as when the discriminator was fed real images from the dataset.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 111 | fprop | Part1:Fake | fill_ | [128] | modern::elementwise_kernel |
| 112 | fprop | Part1:Fake:D:Conv1 | conv2d | N=128,C=1,H=64,W=64,K=64,P=32,Q=32,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeOffsetsKernel |
| 113 | fprop | Part1:Fake:D:Conv1 | conv2d | N=128,C=1,H=64,W=64,K=64,P=32,Q=32,R=4,S=4,ph=1,pw=1,U=2,V=2 | volta_scudnn_128x64_relu_small_nn_v1 |
| 114 | fprop | Part1:Fake:D:LRelu1 | leaky_relu | [128,64,32,32] | modern::elementwise_kernel |
| 115 | fprop | Part1:Fake:D:Conv2 | conv2d | N=128,C=64,H=32,W=32,K=128,P=16,Q=16,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeOffsetsKernel |
| 116 | fprop | Part1:Fake:D:Conv2 | conv2d | N=128,C=64,H=32,W=32,K=128,P=16,Q=16,R=4,S=4,ph=1,pw=1,U=2,V=2 | volta_scudnn_128x128_relu_small_nn_v1 |
| 117 | fprop | Part1:Fake:D:BN2 | __add__ | [];[] | legacy::elementwise_kernel |
| 118 | fprop | Part1:Fake:D:BN2 | batch_norm | [128,128,16,16] | cudnn::detail::bn_fw_tr_1C11_kernel_NCHW |
| 119 | fprop | Part1:Fake:D:LRelu2 | leaky_relu | [128,128,16,16] | modern::elementwise_kernel |
| 120 | fprop | Part1:Fake:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeOffsetsKernel |
| 121 | fprop | Part1:Fake:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | volta_scudnn_128x128_relu_small_nn_v1 |
| 122 | fprop | Part1:Fake:D:BN3 | __add__ | [];[] | legacy::elementwise_kernel |
| 123 | fprop | Part1:Fake:D:BN3 | batch_norm | [128,256,8,8] | cudnn::detail::bn_fw_tr_1C11_kernel_NCHW |
| 124 | fprop | Part1:Fake:D:LRelu3 | leaky_relu | [128,256,8,8] | modern::elementwise_kernel |
| 125 | fprop | Part1:Fake:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeOffsetsKernel |
| 126 | fprop | Part1:Fake:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | volta_scudnn_128x64_relu_small_nn_v1 |
| 127 | fprop | Part1:Fake:D:BN4 | __add__ | [];[] | legacy::elementwise_kernel |
| 128 | fprop | Part1:Fake:D:BN4 | batch_norm | [128,512,4,4] | cudnn::detail::bn_fw_tr_1C11_singleread |
| 129 | fprop | Part1:Fake:D:LRelu4 | leaky_relu | [128,512,4,4] | modern::elementwise_kernel |
| 130 | fprop | Part1:Fake:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | cudnn::gemm::computeOffsetsKernel |
| 131 | fprop | Part1:Fake:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | volta_scudnn_128x32_relu_interior_nn_v1 |
| 132 | fprop | Part1:Fake:D:Sigmoid | sigmoid | [128,1,1,1] | modern::elementwise_kernel |
| 133 | fprop | Part1:Fake:Loss | binary_cross_entropy | T=[(128,),(128,)] | kernelPointwiseApply3 |
| 134 | fprop | Part1:Fake:Loss | binary_cross_entropy | T=[(128,),(128,)] | reduce_kernel |
Discriminator: Backward propagation (fake images).
We now perform back propagation through the discriminator again and calculate and accumulate the gradients. Kernels 135 through 182 are the same as kernels 36 through 83. Kernel 183 adds the losses from real and fake images (for reporting).
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 135 | fprop | Part1:Fake | backward | legacy::elementwise_kernel | |
| 136 | bprop | Part1:Fake:Loss | binary_cross_entropy | T=[(128,),(128,)] | kernelPointwiseApply4 |
| 137 | bprop | Part1:Fake:Loss | binary_cross_entropy | T=[(128,),(128,)] | modern::elementwise_kernel |
| 138 | bprop | Part1:Fake:D:Sigmoid | sigmoid | [128,1,1,1] | modern::elementwise_kernel |
| 139 | bprop | Part1:Fake:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | cudnn::gemm::computeOffsetsKernel |
| 140 | bprop | Part1:Fake:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | cudnn::gemm::computeBOffsetsKernel |
| 141 | bprop | Part1:Fake:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | volta_scudnn_128x128_stridedB_small_nn_v1 |
| 142 | bprop | Part1:Fake:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | cudnn::gemm::computeWgradSplitKOffsetsKernel |
| 143 | bprop | Part1:Fake:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | scalePackedTensor_kernel |
| 144 | bprop | Part1:Fake:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | cudnn::gemm::computeWgradBOffsetsKernel |
| 145 | bprop | Part1:Fake:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | volta_scudnn_128x64_stridedB_splitK_interior_nn_v1 |
| 146 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 147 | bprop | Part1:Fake:D:LRelu4 | leaky_relu | [128,512,4,4] | modern::elementwise_kernel |
| 148 | bprop | Part1:Fake:D:BN4 | batch_norm | [128,512,4,4] | cudnn::detail::bn_bw_1C11_singleread |
| 149 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 150 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 151 | bprop | Part1:Fake:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | scalePackedTensor_kernel |
| 152 | bprop | Part1:Fake:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::detail::dgrad2d_alg1_1 |
| 153 | bprop | Part1:Fake:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeWgradSplitKOffsetsKernel |
| 154 | bprop | Part1:Fake:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | scalePackedTensor_kernel |
| 155 | bprop | Part1:Fake:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeWgradBOffsetsKernel |
| 156 | bprop | Part1:Fake:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | volta_scudnn_128x128_stridedB_splitK_small_nn_v1 |
| 157 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 158 | bprop | Part1:Fake:D:LRelu3 | leaky_relu | [128,256,8,8] | modern::elementwise_kernel |
| 159 | bprop | Part1:Fake:D:BN3 | batch_norm | [128,256,8,8] | cudnn::detail::bn_bw_1C11_kernel_new |
| 160 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 161 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 162 | bprop | Part1:Fake:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | fft2d_r2c_32x32 |
| 163 | bprop | Part1:Fake:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | fft2d_r2c_32x32 |
| 164 | bprop | Part1:Fake:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | volta_gcgemm_32x32_nt |
| 165 | bprop | Part1:Fake:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | fft2d_c2r_32x32 |
| 166 | bprop | Part1:Fake:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeWgradSplitKOffsetsKernel |
| 167 | bprop | Part1:Fake:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | scalePackedTensor_kernel |
| 168 | bprop | Part1:Fake:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeWgradBOffsetsKernel |
| 169 | bprop | Part1:Fake:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | volta_scudnn_128x128_stridedB_splitK_small_nn_v1 |
| 170 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 171 | bprop | Part1:Fake:D:LRelu2 | leaky_relu | [128,128,16,16] | modern::elementwise_kernel |
| 172 | bprop | Part1:Fake:D:BN2 | batch_norm | [128,128,16,16] | cudnn::detail::bn_bw_1C11_kernel_new |
| 173 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 174 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 175 | bprop | Part1:Fake:D:Conv2 | conv2d | N=128,C=64,H=32,W=32,K=128,P=16,Q=16,R=4,S=4,ph=1,pw=1,U=2,V=2 | scalePackedTensor_kernel |
| 176 | bprop | Part1:Fake:D:Conv2 | conv2d | N=128,C=64,H=32,W=32,K=128,P=16,Q=16,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::detail::dgrad2d_alg1_1 |
| 177 | bprop | Part1:Fake:D:Conv2 | conv2d | N=128,C=64,H=32,W=32,K=128,P=16,Q=16,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::detail::wgrad_alg0_engine |
| 178 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 179 | bprop | Part1:Fake:D:LRelu1 | leaky_relu | [128,64,32,32] | modern::elementwise_kernel |
| 180 | bprop | Part1:Fake:D:Conv1 | conv2d | N=128,C=1,H=64,W=64,K=64,P=32,Q=32,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::detail::wgrad_alg0_engine |
| 181 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 182 | fprop | Part1:Fake | mean | [128] | reduce_kernel |
| 183 | fprop | Part1 | __add__ | [];[] | legacy::elementwise_kernel |
Discriminator Optimizer
After calculating and summing up the gradients from the real and fake images, we apply the Adam optimizer on the discriminator weights (parameters). The discriminator has 11 parameters, 1 for each of the 5 convolutions and 2 for each of 3 batch norms (see kernels 1-11). Each call to the Adam optimizer invokes 8 kernels, for a total of 88 kernels (184 through 271). This is not an optimized implementation and one can use the fused Adam implementation from Nvidia Apex.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 184 | fprop | Part1:Optim | mul_ | [64,1,4,4];[] | modern::elementwise_kernel |
| 185 | fprop | Part1:Optim | add_ | [64,1,4,4];[64,1,4,4] | modern::elementwise_kernel |
| 186 | fprop | Part1:Optim | mul_ | [64,1,4,4];[] | modern::elementwise_kernel |
| 187 | fprop | Part1:Optim | addcmul_ | [64,1,4,4];[64,1,4,4];[64,1,4,4] | modern::elementwise_kernel |
| 188 | fprop | Part1:Optim | sqrt | [64,1,4,4] | modern::elementwise_kernel |
| 189 | fprop | Part1:Optim | __truediv__ | [64,1,4,4];[] | modern::elementwise_kernel |
| 190 | fprop | Part1:Optim | add_ | [64,1,4,4];[] | modern::elementwise_kernel |
| 191 | fprop | Part1:Optim | addcdiv_ | [64,1,4,4];[64,1,4,4];[64,1,4,4] | modern::elementwise_kernel |
| 192 | fprop | Part1:Optim | mul_ | [128,64,4,4];[] | modern::elementwise_kernel |
| 193 | fprop | Part1:Optim | add_ | [128,64,4,4];[128,64,4,4] | modern::elementwise_kernel |
| 194 | fprop | Part1:Optim | mul_ | [128,64,4,4];[] | modern::elementwise_kernel |
| 195 | fprop | Part1:Optim | addcmul_ | [128,64,4,4];[128,64,4,4];[128,64,4,4] | modern::elementwise_kernel |
| 196 | fprop | Part1:Optim | sqrt | [128,64,4,4] | modern::elementwise_kernel |
| 197 | fprop | Part1:Optim | __truediv__ | [128,64,4,4];[] | modern::elementwise_kernel |
| 198 | fprop | Part1:Optim | add_ | [128,64,4,4];[] | modern::elementwise_kernel |
| 199 | fprop | Part1:Optim | addcdiv_ | [128,64,4,4];[128,64,4,4];[128,64,4,4] | modern::elementwise_kernel |
| 200 | fprop | Part1:Optim | mul_ | [128];[] | modern::elementwise_kernel |
| 201 | fprop | Part1:Optim | add_ | [128];[128] | modern::elementwise_kernel |
| 202 | fprop | Part1:Optim | mul_ | [128];[] | modern::elementwise_kernel |
| 203 | fprop | Part1:Optim | addcmul_ | [128];[128];[128] | modern::elementwise_kernel |
| 204 | fprop | Part1:Optim | sqrt | [128] | modern::elementwise_kernel |
| 205 | fprop | Part1:Optim | __truediv__ | [128];[] | modern::elementwise_kernel |
| 206 | fprop | Part1:Optim | add_ | [128];[] | modern::elementwise_kernel |
| 207 | fprop | Part1:Optim | addcdiv_ | [128];[128];[128] | modern::elementwise_kernel |
| 208 | fprop | Part1:Optim | mul_ | [128];[] | modern::elementwise_kernel |
| 209 | fprop | Part1:Optim | add_ | [128];[128] | modern::elementwise_kernel |
| 210 | fprop | Part1:Optim | mul_ | [128];[] | modern::elementwise_kernel |
| 211 | fprop | Part1:Optim | addcmul_ | [128];[128];[128] | modern::elementwise_kernel |
| 212 | fprop | Part1:Optim | sqrt | [128] | modern::elementwise_kernel |
| 213 | fprop | Part1:Optim | __truediv__ | [128];[] | modern::elementwise_kernel |
| 214 | fprop | Part1:Optim | add_ | [128];[] | modern::elementwise_kernel |
| 215 | fprop | Part1:Optim | addcdiv_ | [128];[128];[128] | modern::elementwise_kernel |
| 216 | fprop | Part1:Optim | mul_ | [256,128,4,4];[] | modern::elementwise_kernel |
| 217 | fprop | Part1:Optim | add_ | [256,128,4,4];[256,128,4,4] | modern::elementwise_kernel |
| 218 | fprop | Part1:Optim | mul_ | [256,128,4,4];[] | modern::elementwise_kernel |
| 219 | fprop | Part1:Optim | addcmul_ | [256,128,4,4];[256,128,4,4];[256,128,4,4] | modern::elementwise_kernel |
| 220 | fprop | Part1:Optim | sqrt | [256,128,4,4] | modern::elementwise_kernel |
| 221 | fprop | Part1:Optim | __truediv__ | [256,128,4,4];[] | modern::elementwise_kernel |
| 222 | fprop | Part1:Optim | add_ | [256,128,4,4];[] | modern::elementwise_kernel |
| 223 | fprop | Part1:Optim | addcdiv_ | [256,128,4,4];[256,128,4,4];[256,128,4,4] | modern::elementwise_kernel |
| 224 | fprop | Part1:Optim | mul_ | [256];[] | modern::elementwise_kernel |
| 225 | fprop | Part1:Optim | add_ | [256];[256] | modern::elementwise_kernel |
| 226 | fprop | Part1:Optim | mul_ | [256];[] | modern::elementwise_kernel |
| 227 | fprop | Part1:Optim | addcmul_ | [256];[256];[256] | modern::elementwise_kernel |
| 228 | fprop | Part1:Optim | sqrt | [256] | modern::elementwise_kernel |
| 229 | fprop | Part1:Optim | __truediv__ | [256];[] | modern::elementwise_kernel |
| 230 | fprop | Part1:Optim | add_ | [256];[] | modern::elementwise_kernel |
| 231 | fprop | Part1:Optim | addcdiv_ | [256];[256];[256] | modern::elementwise_kernel |
| 232 | fprop | Part1:Optim | mul_ | [256];[] | modern::elementwise_kernel |
| 233 | fprop | Part1:Optim | add_ | [256];[256] | modern::elementwise_kernel |
| 234 | fprop | Part1:Optim | mul_ | [256];[] | modern::elementwise_kernel |
| 235 | fprop | Part1:Optim | addcmul_ | [256];[256];[256] | modern::elementwise_kernel |
| 236 | fprop | Part1:Optim | sqrt | [256] | modern::elementwise_kernel |
| 237 | fprop | Part1:Optim | __truediv__ | [256];[] | modern::elementwise_kernel |
| 238 | fprop | Part1:Optim | add_ | [256];[] | modern::elementwise_kernel |
| 239 | fprop | Part1:Optim | addcdiv_ | [256];[256];[256] | modern::elementwise_kernel |
| 240 | fprop | Part1:Optim | mul_ | [512,256,4,4];[] | modern::elementwise_kernel |
| 241 | fprop | Part1:Optim | add_ | [512,256,4,4];[512,256,4,4] | modern::elementwise_kernel |
| 242 | fprop | Part1:Optim | mul_ | [512,256,4,4];[] | modern::elementwise_kernel |
| 243 | fprop | Part1:Optim | addcmul_ | [512,256,4,4];[512,256,4,4];[512,256,4,4] | modern::elementwise_kernel |
| 244 | fprop | Part1:Optim | sqrt | [512,256,4,4] | modern::elementwise_kernel |
| 245 | fprop | Part1:Optim | __truediv__ | [512,256,4,4];[] | modern::elementwise_kernel |
| 246 | fprop | Part1:Optim | add_ | [512,256,4,4];[] | modern::elementwise_kernel |
| 247 | fprop | Part1:Optim | addcdiv_ | [512,256,4,4];[512,256,4,4];[512,256,4,4] | modern::elementwise_kernel |
| 248 | fprop | Part1:Optim | mul_ | [512];[] | modern::elementwise_kernel |
| 249 | fprop | Part1:Optim | add_ | [512];[512] | modern::elementwise_kernel |
| 250 | fprop | Part1:Optim | mul_ | [512];[] | modern::elementwise_kernel |
| 251 | fprop | Part1:Optim | addcmul_ | [512];[512];[512] | modern::elementwise_kernel |
| 252 | fprop | Part1:Optim | sqrt | [512] | modern::elementwise_kernel |
| 253 | fprop | Part1:Optim | __truediv__ | [512];[] | modern::elementwise_kernel |
| 254 | fprop | Part1:Optim | add_ | [512];[] | modern::elementwise_kernel |
| 255 | fprop | Part1:Optim | addcdiv_ | [512];[512];[512] | modern::elementwise_kernel |
| 256 | fprop | Part1:Optim | mul_ | [512];[] | modern::elementwise_kernel |
| 257 | fprop | Part1:Optim | add_ | [512];[512] | modern::elementwise_kernel |
| 258 | fprop | Part1:Optim | mul_ | [512];[] | modern::elementwise_kernel |
| 259 | fprop | Part1:Optim | addcmul_ | [512];[512];[512] | modern::elementwise_kernel |
| 260 | fprop | Part1:Optim | sqrt | [512] | modern::elementwise_kernel |
| 261 | fprop | Part1:Optim | __truediv__ | [512];[] | modern::elementwise_kernel |
| 262 | fprop | Part1:Optim | add_ | [512];[] | modern::elementwise_kernel |
| 263 | fprop | Part1:Optim | addcdiv_ | [512];[512];[512] | modern::elementwise_kernel |
| 264 | fprop | Part1:Optim | mul_ | [1,512,4,4];[] | modern::elementwise_kernel |
| 265 | fprop | Part1:Optim | add_ | [1,512,4,4];[1,512,4,4] | modern::elementwise_kernel |
| 266 | fprop | Part1:Optim | mul_ | [1,512,4,4];[] | modern::elementwise_kernel |
| 267 | fprop | Part1:Optim | addcmul_ | [1,512,4,4];[1,512,4,4];[1,512,4,4] | modern::elementwise_kernel |
| 268 | fprop | Part1:Optim | sqrt | [1,512,4,4] | modern::elementwise_kernel |
| 269 | fprop | Part1:Optim | __truediv__ | [1,512,4,4];[] | modern::elementwise_kernel |
| 270 | fprop | Part1:Optim | add_ | [1,512,4,4];[] | modern::elementwise_kernel |
| 271 | fprop | Part1:Optim | addcdiv_ | [1,512,4,4];[1,512,4,4];[1,512,4,4] | modern::elementwise_kernel |
Part 2: Train the Generator
Zero out the generator gradients.
At the beginning of part 2, we zero out the gradients of the generator.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 272 | fprop | Part2:G_Gradient | zero_ | [100,512,4,4] | modern::elementwise_kernel |
| 273 | fprop | Part2:G_Gradient | zero_ | [512] | modern::elementwise_kernel |
| 274 | fprop | Part2:G_Gradient | zero_ | [512] | modern::elementwise_kernel |
| 275 | fprop | Part2:G_Gradient | zero_ | [512,256,4,4] | modern::elementwise_kernel |
| 276 | fprop | Part2:G_Gradient | zero_ | [256] | modern::elementwise_kernel |
| 277 | fprop | Part2:G_Gradient | zero_ | [256] | modern::elementwise_kernel |
| 278 | fprop | Part2:G_Gradient | zero_ | [256,128,4,4] | modern::elementwise_kernel |
| 279 | fprop | Part2:G_Gradient | zero_ | [128] | modern::elementwise_kernel |
| 280 | fprop | Part2:G_Gradient | zero_ | [128] | modern::elementwise_kernel |
| 281 | fprop | Part2:G_Gradient | zero_ | [128,64,4,4] | modern::elementwise_kernel |
| 282 | fprop | Part2:G_Gradient | zero_ | [64] | modern::elementwise_kernel |
| 283 | fprop | Part2:G_Gradient | zero_ | [64] | modern::elementwise_kernel |
| 284 | fprop | Part2:G_Gradient | zero_ | [64,1,4,4] | modern::elementwise_kernel |
Discriminator: Forward propagation on fake images from the generator.
In part 1, for training the discriminator, we generated batch_size
i.e. 128 fake images using the generator. Now for training
the generator, we reuse those images and feed them through the
discriminator. However, this time the target label for these images is
set to 1 (kernel 285). Kernels 286 through 308 are the same as before.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 285 | fprop | Part2 | fill_ | [128] | modern::elementwise_kernel |
| 286 | fprop | Part2:D:Conv1 | conv2d | N=128,C=1,H=64,W=64,K=64,P=32,Q=32,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeOffsetsKernel |
| 287 | fprop | Part2:D:Conv1 | conv2d | N=128,C=1,H=64,W=64,K=64,P=32,Q=32,R=4,S=4,ph=1,pw=1,U=2,V=2 | volta_scudnn_128x64_relu_small_nn_v1 |
| 288 | fprop | Part2:D:LRelu1 | leaky_relu | [128,64,32,32] | modern::elementwise_kernel |
| 289 | fprop | Part2:D:Conv2 | conv2d | N=128,C=64,H=32,W=32,K=128,P=16,Q=16,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeOffsetsKernel |
| 290 | fprop | Part2:D:Conv2 | conv2d | N=128,C=64,H=32,W=32,K=128,P=16,Q=16,R=4,S=4,ph=1,pw=1,U=2,V=2 | volta_scudnn_128x128_relu_small_nn_v1 |
| 291 | fprop | Part2:D:BN2 | __add__ | [];[] | legacy::elementwise_kernel |
| 292 | fprop | Part2:D:BN2 | batch_norm | [128,128,16,16] | cudnn::detail::bn_fw_tr_1C11_kernel_NCHW |
| 293 | fprop | Part2:D:LRelu2 | leaky_relu | [128,128,16,16] | modern::elementwise_kernel |
| 294 | fprop | Part2:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeOffsetsKernel |
| 295 | fprop | Part2:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | volta_scudnn_128x128_relu_small_nn_v1 |
| 296 | fprop | Part2:D:BN3 | __add__ | [];[] | legacy::elementwise_kernel |
| 297 | fprop | Part2:D:BN3 | batch_norm | [128,256,8,8] | cudnn::detail::bn_fw_tr_1C11_kernel_NCHW |
| 298 | fprop | Part2:D:LRelu3 | leaky_relu | [128,256,8,8] | modern::elementwise_kernel |
| 299 | fprop | Part2:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeOffsetsKernel |
| 300 | fprop | Part2:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | volta_scudnn_128x64_relu_small_nn_v1 |
| 301 | fprop | Part2:D:BN4 | __add__ | [];[] | legacy::elementwise_kernel |
| 302 | fprop | Part2:D:BN4 | batch_norm | [128,512,4,4] | cudnn::detail::bn_fw_tr_1C11_singleread |
| 303 | fprop | Part2:D:LRelu4 | leaky_relu | [128,512,4,4] | modern::elementwise_kernel |
| 304 | fprop | Part2:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | cudnn::gemm::computeOffsetsKernel |
| 305 | fprop | Part2:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | volta_scudnn_128x32_relu_interior_nn_v1 |
| 306 | fprop | Part2:D:Sigmoid | sigmoid | [128,1,1,1] | modern::elementwise_kernel |
| 307 | fprop | Part2:Loss | binary_cross_entropy | T=[(128,),(128,)] | kernelPointwiseApply3 |
| 308 | fprop | Part2:Loss | binary_cross_entropy | T=[(128,),(128,)] | reduce_kernel |
Discriminator: Backward propagation (fake images).
We now perform back propagation through the discriminator. Kernels 309 through 357 are the same as kernels 36 through 82. The only difference is that we now calculate the data gradient for the first convolution layer as well, which results in 2 additional kernels. Ideally, in part 2, since we don't update the discrimator parameters, we only need the data gradients and not the weight gradients.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 309 | fprop | Part2 | backward | legacy::elementwise_kernel | |
| 310 | bprop | Part2:Loss | binary_cross_entropy | T=[(128,),(128,)] | kernelPointwiseApply4 |
| 311 | bprop | Part2:Loss | binary_cross_entropy | T=[(128,),(128,)] | modern::elementwise_kernel |
| 312 | bprop | Part2:D:Sigmoid | sigmoid | [128,1,1,1] | modern::elementwise_kernel |
| 313 | bprop | Part2:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | cudnn::gemm::computeOffsetsKernel |
| 314 | bprop | Part2:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | cudnn::gemm::computeBOffsetsKernel |
| 315 | bprop | Part2:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | volta_scudnn_128x128_stridedB_small_nn_v1 |
| 316 | bprop | Part2:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | cudnn::gemm::computeWgradSplitKOffsetsKernel |
| 317 | bprop | Part2:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | scalePackedTensor_kernel |
| 318 | bprop | Part2:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | cudnn::gemm::computeWgradBOffsetsKernel |
| 319 | bprop | Part2:D:Conv5 | conv2d | N=128,C=512,H=4,W=4,K=1,P=1,Q=1,R=4,S=4,ph=0,pw=0,U=1,V=1 | volta_scudnn_128x64_stridedB_splitK_interior_nn_v1 |
| 320 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 321 | bprop | Part2:D:LRelu4 | leaky_relu | [128,512,4,4] | modern::elementwise_kernel |
| 322 | bprop | Part2:D:BN4 | batch_norm | [128,512,4,4] | cudnn::detail::bn_bw_1C11_singleread |
| 323 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 324 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 325 | bprop | Part2:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | scalePackedTensor_kernel |
| 326 | bprop | Part2:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::detail::dgrad2d_alg1_1 |
| 327 | bprop | Part2:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeWgradSplitKOffsetsKernel |
| 328 | bprop | Part2:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | scalePackedTensor_kernel |
| 329 | bprop | Part2:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeWgradBOffsetsKernel |
| 330 | bprop | Part2:D:Conv4 | conv2d | N=128,C=256,H=8,W=8,K=512,P=4,Q=4,R=4,S=4,ph=1,pw=1,U=2,V=2 | volta_scudnn_128x128_stridedB_splitK_small_nn_v1 |
| 331 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 332 | bprop | Part2:D:LRelu3 | leaky_relu | [128,256,8,8] | modern::elementwise_kernel |
| 333 | bprop | Part2:D:BN3 | batch_norm | [128,256,8,8] | cudnn::detail::bn_bw_1C11_kernel_new |
| 334 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 335 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 336 | bprop | Part2:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | fft2d_r2c_32x32 |
| 337 | bprop | Part2:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | fft2d_r2c_32x32 |
| 338 | bprop | Part2:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | volta_gcgemm_32x32_nt |
| 339 | bprop | Part2:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | fft2d_c2r_32x32 |
| 340 | bprop | Part2:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeWgradSplitKOffsetsKernel |
| 341 | bprop | Part2:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | scalePackedTensor_kernel |
| 342 | bprop | Part2:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::gemm::computeWgradBOffsetsKernel |
| 343 | bprop | Part2:D:Conv3 | conv2d | N=128,C=128,H=16,W=16,K=256,P=8,Q=8,R=4,S=4,ph=1,pw=1,U=2,V=2 | volta_scudnn_128x128_stridedB_splitK_small_nn_v1 |
| 344 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 345 | bprop | Part2:D:LRelu2 | leaky_relu | [128,128,16,16] | modern::elementwise_kernel |
| 346 | bprop | Part2:D:BN2 | batch_norm | [128,128,16,16] | cudnn::detail::bn_bw_1C11_kernel_new |
| 347 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 348 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 349 | bprop | Part2:D:Conv2 | conv2d | N=128,C=64,H=32,W=32,K=128,P=16,Q=16,R=4,S=4,ph=1,pw=1,U=2,V=2 | scalePackedTensor_kernel |
| 350 | bprop | Part2:D:Conv2 | conv2d | N=128,C=64,H=32,W=32,K=128,P=16,Q=16,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::detail::dgrad2d_alg1_1 |
| 351 | bprop | Part2:D:Conv2 | conv2d | N=128,C=64,H=32,W=32,K=128,P=16,Q=16,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::detail::wgrad_alg0_engine |
| 352 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 353 | bprop | Part2:D:LRelu1 | leaky_relu | [128,64,32,32] | modern::elementwise_kernel |
| 354 | bprop | Part2:D:Conv1 | conv2d | N=128,C=1,H=64,W=64,K=64,P=32,Q=32,R=4,S=4,ph=1,pw=1,U=2,V=2 | scalePackedTensor_kernel |
| 355 | bprop | Part2:D:Conv1 | conv2d | N=128,C=1,H=64,W=64,K=64,P=32,Q=32,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::detail::dgrad_engine |
| 356 | bprop | Part2:D:Conv1 | conv2d | N=128,C=1,H=64,W=64,K=64,P=32,Q=32,R=4,S=4,ph=1,pw=1,U=2,V=2 | cudnn::detail::wgrad_alg0_engine |
| 357 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
Generator: Backward propagation.
We now perform back propagation through the generator.
Kernels 358-361 correspond to bprop through the fifth transposed convolution layer.
Kernels 363,364,367-369 correspond to bprop through the fourth transposed convolution layer.
Kernels 371,372,375-380 correspond to bprop through the third transposed convolution layer.
Kernels 382,383,386-391 correspond to bprop through the second transposed convolution layer.
Kernels 393,394,397-400 correspond to bprop through the first transposed convolution layer.
Kernels with the op add_, most likely correspond to gradient
accumulation i.e. adding the gradients to the previously zeroed out
gradient tensors. Kernel 402 calculates the average loss (for reporting).
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 358 | bprop | Part1:Fake:G:Tanh | tanh | [128,1,64,64] | modern::elementwise_kernel |
| 359 | bprop | Part1:Fake:G:ConvT5 | conv_transpose2d | T=[(128,64,32,32),(64,1,4,4)] | cudnn::gemm::computeOffsetsKernel |
| 360 | bprop | Part1:Fake:G:ConvT5 | conv_transpose2d | T=[(128,64,32,32),(64,1,4,4)] | volta_scudnn_128x64_relu_small_nn_v1 |
| 361 | bprop | Part1:Fake:G:ConvT5 | conv_transpose2d | T=[(128,64,32,32),(64,1,4,4)] | cudnn::detail::wgrad_alg0_engine |
| 362 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 363 | bprop | Part1:Fake:G:Relu4 | relu | [128,64,32,32] | modern::elementwise_kernel |
| 364 | bprop | Part1:Fake:G:BN4 | batch_norm | [128,64,32,32] | cudnn::detail::bn_bw_1C11_kernel_new |
| 365 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 366 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 367 | bprop | Part1:Fake:G:ConvT4 | conv_transpose2d | T=[(128,128,16,16),(128,64,4,4)] | cudnn::gemm::computeOffsetsKernel |
| 368 | bprop | Part1:Fake:G:ConvT4 | conv_transpose2d | T=[(128,128,16,16),(128,64,4,4)] | volta_scudnn_128x128_relu_small_nn_v1 |
| 369 | bprop | Part1:Fake:G:ConvT4 | conv_transpose2d | T=[(128,128,16,16),(128,64,4,4)] | cudnn::detail::wgrad_alg0_engine |
| 370 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 371 | bprop | Part1:Fake:G:Relu3 | relu | [128,128,16,16] | modern::elementwise_kernel |
| 372 | bprop | Part1:Fake:G:BN3 | batch_norm | [128,128,16,16] | cudnn::detail::bn_bw_1C11_kernel_new |
| 373 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 374 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 375 | bprop | Part1:Fake:G:ConvT3 | conv_transpose2d | T=[(128,256,8,8),(256,128,4,4)] | cudnn::gemm::computeOffsetsKernel |
| 376 | bprop | Part1:Fake:G:ConvT3 | conv_transpose2d | T=[(128,256,8,8),(256,128,4,4)] | volta_scudnn_128x128_relu_small_nn_v1 |
| 377 | bprop | Part1:Fake:G:ConvT3 | conv_transpose2d | T=[(128,256,8,8),(256,128,4,4)] | cudnn::gemm::computeWgradSplitKOffsetsKernel |
| 378 | bprop | Part1:Fake:G:ConvT3 | conv_transpose2d | T=[(128,256,8,8),(256,128,4,4)] | scalePackedTensor_kernel |
| 379 | bprop | Part1:Fake:G:ConvT3 | conv_transpose2d | T=[(128,256,8,8),(256,128,4,4)] | cudnn::gemm::computeWgradBOffsetsKernel |
| 380 | bprop | Part1:Fake:G:ConvT3 | conv_transpose2d | T=[(128,256,8,8),(256,128,4,4)] | volta_scudnn_128x128_stridedB_splitK_small_nn_v1 |
| 381 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 382 | bprop | Part1:Fake:G:Relu2 | relu | [128,256,8,8] | modern::elementwise_kernel |
| 383 | bprop | Part1:Fake:G:BN2 | batch_norm | [128,256,8,8] | cudnn::detail::bn_bw_1C11_kernel_new |
| 384 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 385 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 386 | bprop | Part1:Fake:G:ConvT2 | conv_transpose2d | T=[(128,512,4,4),(512,256,4,4)] | cudnn::gemm::computeOffsetsKernel |
| 387 | bprop | Part1:Fake:G:ConvT2 | conv_transpose2d | T=[(128,512,4,4),(512,256,4,4)] | volta_scudnn_128x64_relu_small_nn_v1 |
| 388 | bprop | Part1:Fake:G:ConvT2 | conv_transpose2d | T=[(128,512,4,4),(512,256,4,4)] | cudnn::gemm::computeWgradSplitKOffsetsKernel |
| 389 | bprop | Part1:Fake:G:ConvT2 | conv_transpose2d | T=[(128,512,4,4),(512,256,4,4)] | scalePackedTensor_kernel |
| 390 | bprop | Part1:Fake:G:ConvT2 | conv_transpose2d | T=[(128,512,4,4),(512,256,4,4)] | cudnn::gemm::computeWgradBOffsetsKernel |
| 391 | bprop | Part1:Fake:G:ConvT2 | conv_transpose2d | T=[(128,512,4,4),(512,256,4,4)] | volta_scudnn_128x128_stridedB_splitK_small_nn_v1 |
| 392 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 393 | bprop | Part1:Fake:G:Relu1 | relu | [128,512,4,4] | modern::elementwise_kernel |
| 394 | bprop | Part1:Fake:G:BN1 | batch_norm | [128,512,4,4] | cudnn::detail::bn_bw_1C11_singleread |
| 395 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 396 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 397 | bprop | Part1:Fake:G:ConvT1 | conv_transpose2d | T=[(128,100,1,1),(100,512,4,4)] | cudnn::gemm::computeWgradSplitKOffsetsKernel |
| 398 | bprop | Part1:Fake:G:ConvT1 | conv_transpose2d | T=[(128,100,1,1),(100,512,4,4)] | scalePackedTensor_kernel |
| 399 | bprop | Part1:Fake:G:ConvT1 | conv_transpose2d | T=[(128,100,1,1),(100,512,4,4)] | cudnn::gemm::computeWgradBOffsetsKernel |
| 400 | bprop | Part1:Fake:G:ConvT1 | conv_transpose2d | T=[(128,100,1,1),(100,512,4,4)] | volta_scudnn_128x64_stridedB_splitK_interior_nn_v1 |
| 401 | fprop | - | add_ | na=na, | modern::elementwise_kernel |
| 402 | fprop | Part2 | mean | [128] | reduce_kernel |
Generator Optimizer
The last step is to apply the Adam optimizer on the generator weights. The generator has 13 parameters, 1 for each of the 5 transposed convolutions and 2 for each of the 4 batch norms (see kernels 272-284). Each call to the Adam optimizer invokes 8 kernels, for a total of 104 kernels (403 through 506). This is not an optimized implementation and one can use the fused Adam implementation from Nvidia Apex.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 403 | fprop | Part2:Optim | mul_ | [100,512,4,4];[] | modern::elementwise_kernel |
| 404 | fprop | Part2:Optim | add_ | [100,512,4,4];[100,512,4,4] | modern::elementwise_kernel |
| 405 | fprop | Part2:Optim | mul_ | [100,512,4,4];[] | modern::elementwise_kernel |
| 406 | fprop | Part2:Optim | addcmul_ | [100,512,4,4];[100,512,4,4];[100,512,4,4] | modern::elementwise_kernel |
| 407 | fprop | Part2:Optim | sqrt | [100,512,4,4] | modern::elementwise_kernel |
| 408 | fprop | Part2:Optim | __truediv__ | [100,512,4,4];[] | modern::elementwise_kernel |
| 409 | fprop | Part2:Optim | add_ | [100,512,4,4];[] | modern::elementwise_kernel |
| 410 | fprop | Part2:Optim | addcdiv_ | [100,512,4,4];[100,512,4,4];[100,512,4,4] | modern::elementwise_kernel |
| 411 | fprop | Part2:Optim | mul_ | [512];[] | modern::elementwise_kernel |
| 412 | fprop | Part2:Optim | add_ | [512];[512] | modern::elementwise_kernel |
| 413 | fprop | Part2:Optim | mul_ | [512];[] | modern::elementwise_kernel |
| 414 | fprop | Part2:Optim | addcmul_ | [512];[512];[512] | modern::elementwise_kernel |
| 415 | fprop | Part2:Optim | sqrt | [512] | modern::elementwise_kernel |
| 416 | fprop | Part2:Optim | __truediv__ | [512];[] | modern::elementwise_kernel |
| 417 | fprop | Part2:Optim | add_ | [512];[] | modern::elementwise_kernel |
| 418 | fprop | Part2:Optim | addcdiv_ | [512];[512];[512] | modern::elementwise_kernel |
| 419 | fprop | Part2:Optim | mul_ | [512];[] | modern::elementwise_kernel |
| 420 | fprop | Part2:Optim | add_ | [512];[512] | modern::elementwise_kernel |
| 421 | fprop | Part2:Optim | mul_ | [512];[] | modern::elementwise_kernel |
| 422 | fprop | Part2:Optim | addcmul_ | [512];[512];[512] | modern::elementwise_kernel |
| 423 | fprop | Part2:Optim | sqrt | [512] | modern::elementwise_kernel |
| 424 | fprop | Part2:Optim | __truediv__ | [512];[] | modern::elementwise_kernel |
| 425 | fprop | Part2:Optim | add_ | [512];[] | modern::elementwise_kernel |
| 426 | fprop | Part2:Optim | addcdiv_ | [512];[512];[512] | modern::elementwise_kernel |
| 427 | fprop | Part2:Optim | mul_ | [512,256,4,4];[] | modern::elementwise_kernel |
| 428 | fprop | Part2:Optim | add_ | [512,256,4,4];[512,256,4,4] | modern::elementwise_kernel |
| 429 | fprop | Part2:Optim | mul_ | [512,256,4,4];[] | modern::elementwise_kernel |
| 430 | fprop | Part2:Optim | addcmul_ | [512,256,4,4];[512,256,4,4];[512,256,4,4] | modern::elementwise_kernel |
| 431 | fprop | Part2:Optim | sqrt | [512,256,4,4] | modern::elementwise_kernel |
| 432 | fprop | Part2:Optim | __truediv__ | [512,256,4,4];[] | modern::elementwise_kernel |
| 433 | fprop | Part2:Optim | add_ | [512,256,4,4];[] | modern::elementwise_kernel |
| 434 | fprop | Part2:Optim | addcdiv_ | [512,256,4,4];[512,256,4,4];[512,256,4,4] | modern::elementwise_kernel |
| 435 | fprop | Part2:Optim | mul_ | [256];[] | modern::elementwise_kernel |
| 436 | fprop | Part2:Optim | add_ | [256];[256] | modern::elementwise_kernel |
| 437 | fprop | Part2:Optim | mul_ | [256];[] | modern::elementwise_kernel |
| 438 | fprop | Part2:Optim | addcmul_ | [256];[256];[256] | modern::elementwise_kernel |
| 439 | fprop | Part2:Optim | sqrt | [256] | modern::elementwise_kernel |
| 440 | fprop | Part2:Optim | __truediv__ | [256];[] | modern::elementwise_kernel |
| 441 | fprop | Part2:Optim | add_ | [256];[] | modern::elementwise_kernel |
| 442 | fprop | Part2:Optim | addcdiv_ | [256];[256];[256] | modern::elementwise_kernel |
| 443 | fprop | Part2:Optim | mul_ | [256];[] | modern::elementwise_kernel |
| 444 | fprop | Part2:Optim | add_ | [256];[256] | modern::elementwise_kernel |
| 445 | fprop | Part2:Optim | mul_ | [256];[] | modern::elementwise_kernel |
| 446 | fprop | Part2:Optim | addcmul_ | [256];[256];[256] | modern::elementwise_kernel |
| 447 | fprop | Part2:Optim | sqrt | [256] | modern::elementwise_kernel |
| 448 | fprop | Part2:Optim | __truediv__ | [256];[] | modern::elementwise_kernel |
| 449 | fprop | Part2:Optim | add_ | [256];[] | modern::elementwise_kernel |
| 450 | fprop | Part2:Optim | addcdiv_ | [256];[256];[256] | modern::elementwise_kernel |
| 451 | fprop | Part2:Optim | mul_ | [256,128,4,4];[] | modern::elementwise_kernel |
| 452 | fprop | Part2:Optim | add_ | [256,128,4,4];[256,128,4,4] | modern::elementwise_kernel |
| 453 | fprop | Part2:Optim | mul_ | [256,128,4,4];[] | modern::elementwise_kernel |
| 454 | fprop | Part2:Optim | addcmul_ | [256,128,4,4];[256,128,4,4];[256,128,4,4] | modern::elementwise_kernel |
| 455 | fprop | Part2:Optim | sqrt | [256,128,4,4] | modern::elementwise_kernel |
| 456 | fprop | Part2:Optim | __truediv__ | [256,128,4,4];[] | modern::elementwise_kernel |
| 457 | fprop | Part2:Optim | add_ | [256,128,4,4];[] | modern::elementwise_kernel |
| 458 | fprop | Part2:Optim | addcdiv_ | [256,128,4,4];[256,128,4,4];[256,128,4,4] | modern::elementwise_kernel |
| 459 | fprop | Part2:Optim | mul_ | [128];[] | modern::elementwise_kernel |
| 460 | fprop | Part2:Optim | add_ | [128];[128] | modern::elementwise_kernel |
| 461 | fprop | Part2:Optim | mul_ | [128];[] | modern::elementwise_kernel |
| 462 | fprop | Part2:Optim | addcmul_ | [128];[128];[128] | modern::elementwise_kernel |
| 463 | fprop | Part2:Optim | sqrt | [128] | modern::elementwise_kernel |
| 464 | fprop | Part2:Optim | __truediv__ | [128];[] | modern::elementwise_kernel |
| 465 | fprop | Part2:Optim | add_ | [128];[] | modern::elementwise_kernel |
| 466 | fprop | Part2:Optim | addcdiv_ | [128];[128];[128] | modern::elementwise_kernel |
| 467 | fprop | Part2:Optim | mul_ | [128];[] | modern::elementwise_kernel |
| 468 | fprop | Part2:Optim | add_ | [128];[128] | modern::elementwise_kernel |
| 469 | fprop | Part2:Optim | mul_ | [128];[] | modern::elementwise_kernel |
| 470 | fprop | Part2:Optim | addcmul_ | [128];[128];[128] | modern::elementwise_kernel |
| 471 | fprop | Part2:Optim | sqrt | [128] | modern::elementwise_kernel |
| 472 | fprop | Part2:Optim | __truediv__ | [128];[] | modern::elementwise_kernel |
| 473 | fprop | Part2:Optim | add_ | [128];[] | modern::elementwise_kernel |
| 474 | fprop | Part2:Optim | addcdiv_ | [128];[128];[128] | modern::elementwise_kernel |
| 475 | fprop | Part2:Optim | mul_ | [128,64,4,4];[] | modern::elementwise_kernel |
| 476 | fprop | Part2:Optim | add_ | [128,64,4,4];[128,64,4,4] | modern::elementwise_kernel |
| 477 | fprop | Part2:Optim | mul_ | [128,64,4,4];[] | modern::elementwise_kernel |
| 478 | fprop | Part2:Optim | addcmul_ | [128,64,4,4];[128,64,4,4];[128,64,4,4] | modern::elementwise_kernel |
| 479 | fprop | Part2:Optim | sqrt | [128,64,4,4] | modern::elementwise_kernel |
| 480 | fprop | Part2:Optim | __truediv__ | [128,64,4,4];[] | modern::elementwise_kernel |
| 481 | fprop | Part2:Optim | add_ | [128,64,4,4];[] | modern::elementwise_kernel |
| 482 | fprop | Part2:Optim | addcdiv_ | [128,64,4,4];[128,64,4,4];[128,64,4,4] | modern::elementwise_kernel |
| 483 | fprop | Part2:Optim | mul_ | [64];[] | modern::elementwise_kernel |
| 484 | fprop | Part2:Optim | add_ | [64];[64] | modern::elementwise_kernel |
| 485 | fprop | Part2:Optim | mul_ | [64];[] | modern::elementwise_kernel |
| 486 | fprop | Part2:Optim | addcmul_ | [64];[64];[64] | modern::elementwise_kernel |
| 487 | fprop | Part2:Optim | sqrt | [64] | modern::elementwise_kernel |
| 488 | fprop | Part2:Optim | __truediv__ | [64];[] | modern::elementwise_kernel |
| 489 | fprop | Part2:Optim | add_ | [64];[] | modern::elementwise_kernel |
| 490 | fprop | Part2:Optim | addcdiv_ | [64];[64];[64] | modern::elementwise_kernel |
| 491 | fprop | Part2:Optim | mul_ | [64];[] | modern::elementwise_kernel |
| 492 | fprop | Part2:Optim | add_ | [64];[64] | modern::elementwise_kernel |
| 493 | fprop | Part2:Optim | mul_ | [64];[] | modern::elementwise_kernel |
| 494 | fprop | Part2:Optim | addcmul_ | [64];[64];[64] | modern::elementwise_kernel |
| 495 | fprop | Part2:Optim | sqrt | [64] | modern::elementwise_kernel |
| 496 | fprop | Part2:Optim | __truediv__ | [64];[] | modern::elementwise_kernel |
| 497 | fprop | Part2:Optim | add_ | [64];[] | modern::elementwise_kernel |
| 498 | fprop | Part2:Optim | addcdiv_ | [64];[64];[64] | modern::elementwise_kernel |
| 499 | fprop | Part2:Optim | mul_ | [64,1,4,4];[] | modern::elementwise_kernel |
| 500 | fprop | Part2:Optim | add_ | [64,1,4,4];[64,1,4,4] | modern::elementwise_kernel |
| 501 | fprop | Part2:Optim | mul_ | [64,1,4,4];[] | modern::elementwise_kernel |
| 502 | fprop | Part2:Optim | addcmul_ | [64,1,4,4];[64,1,4,4];[64,1,4,4] | modern::elementwise_kernel |
| 503 | fprop | Part2:Optim | sqrt | [64,1,4,4] | modern::elementwise_kernel |
| 504 | fprop | Part2:Optim | __truediv__ | [64,1,4,4];[] | modern::elementwise_kernel |
| 505 | fprop | Part2:Optim | add_ | [64,1,4,4];[] | modern::elementwise_kernel |
| 506 | fprop | Part2:Optim | addcdiv_ | [64,1,4,4];[64,1,4,4];[64,1,4,4] | modern::elementwise_kernel |