Bidirectional Encoder Representations from Transformers (BERT)
September 20, 2020
Bidirectional Encoder Representations from Transformers (BERT) is a language representation model developed by Google. It obtained state of the art results on 11 natural language processing tasks. Due to its phenomenal success, it is one of the benchmarks in MLPerf. It is conceptually simple and consists of 24 Transformer Encoder blocks. However, a single training step (forward and backward propagation) of BERT pre-training invokes about 1800 GPU CUDA kernels. The best way to understand a DL network and GPU performance is to understand every single CUDA kernel i.e. which layer of the network invoked the kernel, with what arguments (tensor shapes and datatypes) and in which direction (forward propagation or backward propagation).
In this post, we will categorize every kernel used in the training of
BERT. All the information in the tables below was obtaining using Nvidia's
PyTorch Profiler, PyProf, on a Turing T4 GPU. The information below
is only a subset of what is provided by PyProf. The code and instructions
for obtaining a detailed profile are here. Note that different GPUs
will have slightly different kernel names e.g. volta_* as opposed to
turing_*.
Model Parameters
The parameters in the profiled code are as follows. These were obtained
from Nvidia Deep Learning Examples. For the purpose of profiling,
we reduced the number of encoder blocks (num_hidden_layers) from
24 to 2.
attention_probs_dropout_prob: 0.1
hidden_act: "gelu"
hidden_dropout_prob: 0.1
hidden_size: 1024
initializer_range: 0.02
intermediate_size: 4096
max_position_embeddings: 512
num_attention_heads: 16
num_hidden_layers: 2
type_vocab_size: 2
vocab_size: 30522Other relevant parameters for pre-training phase 1 are as follows. The values of duplication factor, masked language model probability are important for model convergence but not for iteration time.
Batch size: 4
Sequence length: 128GPU Kernels
The tables below show the GPU kernels invoked in 1 training step of pre-training phase 1. For every GPU kernel we show the direction (fprop, bprop), name of the layer, name of the operation, and the input tensor shapes / matrix dimensions for the operation. PyProf provides a lot of additional information for every GPU kernel e.g. grid dimensions, block dimensions, silicon time, datatypes, flops, bytes, tensor core usage and so on.
Attention Mask
Kernels 1-3 convert, subtract and rescale the attention mask before feeding it to the encoder blocks.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 1 | fprop | - | to | [4,1,1,128] | legacy::elementwise_kernel |
| 2 | fprop | - | __rsub__ | [4,1,1,128];[] | modern::elementwise_kernel |
| 3 | fprop | - | __mul__ | [4,1,1,128];[] | modern::elementwise_kernel |
Embedding
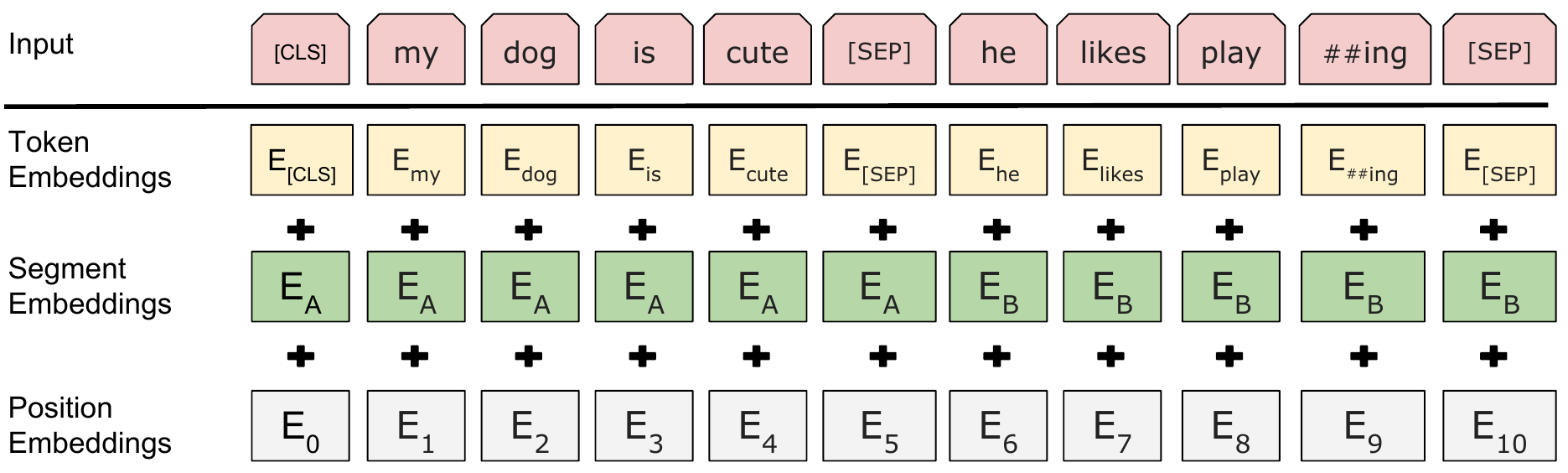
BERT has three input embeddings viz. token, segment and position
as shown below. The size of the token embedding matrix is [30528, 1024] which is ~ [vocab_size, hidden_size]. The size of the position
embedding matrix is [512, 1024] which is [max_position_embeddings, vocab_size] even though in pre-training phase 1, the maximum sequence
length is 128. The size of the token embedding matrix is [2, 1024]
which is [type_vocab_size, hidden_size]. The embeddings are added
together followed by LayerNorm and Dropout. The output dimensions are
[batch_size, sequence_length, hidden_size].
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 4 | fprop | Embedding | arange | [128] | elementwise_kernel_with_index |
| 5 | fprop | Embedding:Token | embedding | [4,128];[30528,1024] | indexSelectLargeIndex |
| 6 | fprop | Embedding:Position | embedding | [4,128];[512,1024] | legacy::elementwise_kernel |
| 7 | fprop | Embedding:Position | embedding | [4,128];[512,1024] | indexSelectLargeIndex |
| 8 | fprop | Embedding:Segment | embedding | [4,128];[2,1024] | indexSelectLargeIndex |
| 9 | fprop | Embedding:Total | __add__ | [4,128,1024];[4,128,1024] | modern::elementwise_kernel |
| 10 | fprop | Embedding:Total | __add__ | [4,128,1024];[4,128,1024] | modern::elementwise_kernel |
| 11 | fprop | Embedding:LayerNorm | forward_affine | [4,128,1024];[1024];[1024] | cuApplyLayerNorm |
| 12 | fprop | Embedding | dropout | [4,128,1024] | fused_dropout_kernel |
Encoder
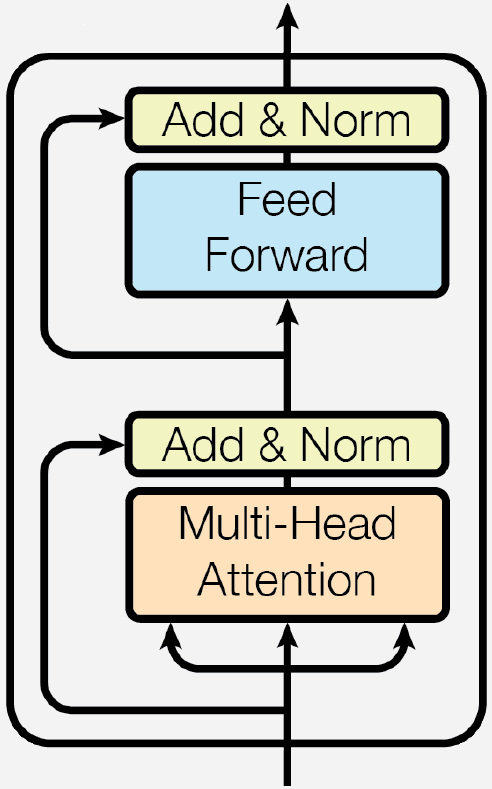
BERTlarge has 24 Transformer Encoder blocks. All encoder
blocks are exactly the same. Each encoder block consists of a Multi-Head Attention + Residual + Layer Norm sub-block followed by a Feed Forward Network + Residual + Layer Norm sub-block as shown below. The multi-head
attention has num_attention_heads heads, 16 in this network. This
article explains multi-head attention in more detail. For
the purpose of profiling, we reduced the number of encoder blocks
(num_hidden_layers) from 24 to 2. In the following two tables, we will
look at the kernels associated with the two sub blocks of encoder 0.
Encoder 0: Multi-Head Attention
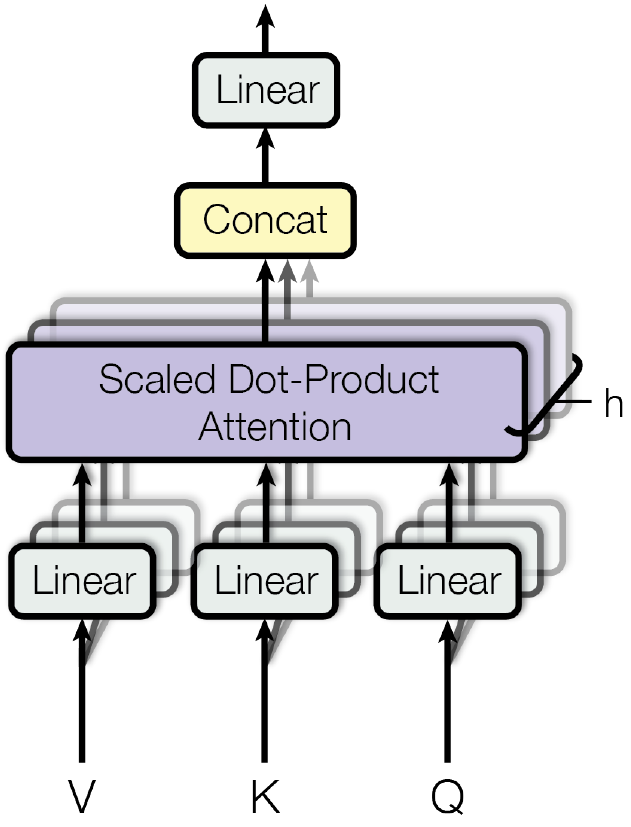
Kernels 13 through 18 correspond to the projection of $Q$, $K$ and $V$
vectors from hidden_size to hidden_size. Contrary to what is shown
in the middle image above, we do one big projection from hidden_size
to hidden_size (1024 to 1024) as opposed to 16 smaller projections
(64 to 64). Note that 1024 = 16 * 64.
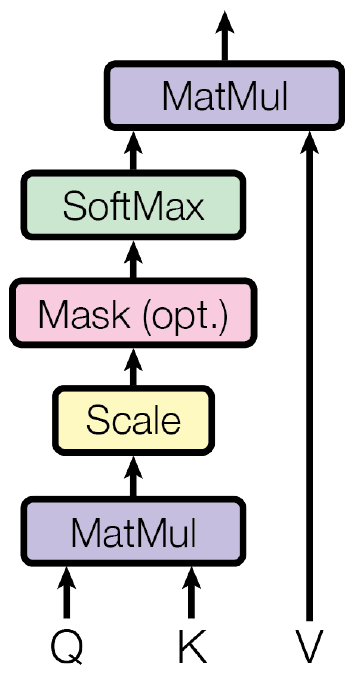
Kernels 19-21 correspond to the batched matrix multiply operation
for $Q.K^T$ where each matrix multiplication has the shape [128, 64] x [64, 128] and the number of batches is [4, 16]. The output shape is
[4, 16, 128, 128].
Kernels 22-25 correspond to the scale, mask, softmax and dropout layers.
Kernels 26 and 27 correspond to the batched matrix multiply operation
for $Q.K^T.V$ where each matrix multiplication has the shape [128, 128] x [128, 64] and the number of batches is [4, 16]. The output shape
is [4, 16, 128, 64]. The output is rearranged to [4, 128, 16, 64].
Kernel 28 combines the 16 attention heads back together to give us
[4, 128, 1024] as before.
Kernels 29 and 30 correspond to the Linear layer (top block in the
middle image).
Kernels 31-33 correspond to Dropout, Residual and Layer Norm layers at
the end of the first sub-block. Note that the Dropout layer is not shown
in the images but is typically used.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 13 | fprop | Enc_0:Attn:SelfAttn:Q_Proj | linear | M=1024,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_tn |
| 14 | fprop | Enc_0:Attn:SelfAttn:Q_Proj | bias | M=1024,N=(4,128), | legacy::elementwise_kernel |
| 15 | fprop | Enc_0:Attn:SelfAttn:K_Proj | linear | M=1024,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_tn |
| 16 | fprop | Enc_0:Attn:SelfAttn:K_Proj | bias | M=1024,N=(4,128), | legacy::elementwise_kernel |
| 17 | fprop | Enc_0:Attn:SelfAttn:V_Proj | linear | M=1024,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_tn |
| 18 | fprop | Enc_0:Attn:SelfAttn:V_Proj | bias | M=1024,N=(4,128), | legacy::elementwise_kernel |
| 19 | fprop | Enc_0:Attn:SelfAttn:Q.K | matmul | A=(4,16,128,64),B=(4,16,64,128), | legacy::elementwise_kernel |
| 20 | fprop | Enc_0:Attn:SelfAttn:Q.K | matmul | A=(4,16,128,64),B=(4,16,64,128), | legacy::elementwise_kernel |
| 21 | fprop | Enc_0:Attn:SelfAttn:Q.K | matmul | A=(4,16,128,64),B=(4,16,64,128), | turing_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 22 | fprop | Enc_0:Attn:SelfAttn:Scale | __truediv__ | [4,16,128,128];[] | modern::elementwise_kernel |
| 23 | fprop | Enc_0:Attn:SelfAttn:Mask | __add__ | [4,16,128,128];[4,1,1,128] | legacy::elementwise_kernel |
| 24 | fprop | Enc_0:Attn:SelfAttn:SoftMax | softmax | [4,16,128,128] | softmax_warp_forward |
| 25 | fprop | Enc_0:Attn:SelfAttn:Dropout | dropout | [4,16,128,128] | fused_dropout_kernel |
| 26 | fprop | Enc_0:Attn:SelfAttn:QKV | matmul | A=(4,16,128,128),B=(4,16,128,64), | legacy::elementwise_kernel |
| 27 | fprop | Enc_0:Attn:SelfAttn:QKV | matmul | A=(4,16,128,128),B=(4,16,128,64), | turing_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 28 | fprop | Enc_0:Attn:SelfAttention | contiguous | T=(4,128,16,64), | legacy::elementwise_kernel |
| 29 | fprop | Enc_0:Attn:Output | linear | M=1024,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_tn |
| 30 | fprop | Enc_0:Attn:Output | bias | M=1024,N=(4,128), | legacy::elementwise_kernel |
| 31 | fprop | Enc_0:Attn:Output | dropout | [4,128,1024] | fused_dropout_kernel |
| 32 | fprop | Enc_0:Attn:Output | __add__ | [4,128,1024];[4,128,1024] | modern::elementwise_kernel |
| 33 | fprop | Enc_0:Attn:Output:LayerNorm | forward_affine | T=[(4,128,1024),(1024,),(1024,)], | cuApplyLayerNorm |
Encoder 0: Feed Forward Network (FFN)
The FFN consists of two linear transformations with a GELU activation
(hidden_act) in between. The input and output dimensions are equal to
hidden_size which is 1024 in this example. The intermediate dimension
is equal to intermediate_size which is 4096 in this example.
Kernels 34 and 35 correspond to the first Linear layer and GELU activation
respectively. The GELU activation is a fused (PyTorch JITted) kernel
and hence shows up as a FusionGroup.
Kernels 36 and 37 correspond to the second Linear layer.
Kernels 38-40 correspond to Dropout, Residual and Layer Norm layers at
the end of the second sub-block.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 34 | fprop | Enc_0:FFN | linear | M=4096,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x256_ldg8_f2f_tn |
| 35 | fprop | Enc_0:FFN | FusionGroup | na | kernel_0 |
| 36 | fprop | Enc_0:FFN | linear | M=1024,N=(4,128),K=4096, | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_tn |
| 37 | fprop | Enc_0:FFN | bias | M=1024,N=(4,128), | legacy::elementwise_kernel |
| 38 | fprop | Enc_0:FFN | dropout | [4,128,1024] | fused_dropout_kernel |
| 39 | fprop | Enc_0:FFN | __add__ | [4,128,1024];[4,128,1024] | modern::elementwise_kernel |
| 40 | fprop | Enc_0:FFN:LayerNorm | forward_affine | T=[(4,128,1024),(1024,),(1024,)], | cuApplyLayerNorm |
Encoder 1
Kernels 41 through 68 correspond to the second encoder block. They are exactly the same as the first encoder block.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 41 | fprop | Enc_1:Attn:SelfAttn:Q_Proj | linear | M=1024,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_tn |
| 42 | fprop | Enc_1:Attn:SelfAttn:Q_Proj | bias | M=1024,N=(4,128), | legacy::elementwise_kernel |
| 43 | fprop | Enc_1:Attn:SelfAttn:K_Proj | linear | M=1024,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_tn |
| 44 | fprop | Enc_1:Attn:SelfAttn:K_Proj | bias | M=1024,N=(4,128), | legacy::elementwise_kernel |
| 45 | fprop | Enc_1:Attn:SelfAttn:V_Proj | linear | M=1024,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_tn |
| 46 | fprop | Enc_1:Attn:SelfAttn:V_Proj | bias | M=1024,N=(4,128), | legacy::elementwise_kernel |
| 47 | fprop | Enc_1:Attn:SelfAttn:Q.K | matmul | A=(4,16,128,64),B=(4,16,64,128), | legacy::elementwise_kernel |
| 48 | fprop | Enc_1:Attn:SelfAttn:Q.K | matmul | A=(4,16,128,64),B=(4,16,64,128), | legacy::elementwise_kernel |
| 49 | fprop | Enc_1:Attn:SelfAttn:Q.K | matmul | A=(4,16,128,64),B=(4,16,64,128), | turing_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 50 | fprop | Enc_1:Attn:SelfAttn:Scale | __truediv__ | [4,16,128,128];[] | modern::elementwise_kernel |
| 51 | fprop | Enc_1:Attn:SelfAttn:Mask | __add__ | [4,16,128,128];[4,1,1,128] | legacy::elementwise_kernel |
| 52 | fprop | Enc_1:Attn:SelfAttn:SoftMax | softmax | [4,16,128,128] | softmax_warp_forward |
| 53 | fprop | Enc_1:Attn:SelfAttn:Dropout | dropout | [4,16,128,128] | fused_dropout_kernel |
| 54 | fprop | Enc_1:Attn:SelfAttn:QKV | matmul | A=(4,16,128,128),B=(4,16,128,64), | legacy::elementwise_kernel |
| 55 | fprop | Enc_1:Attn:SelfAttn:QKV | matmul | A=(4,16,128,128),B=(4,16,128,64), | turing_fp16_s884gemm_fp16_64x64_ldg8_f2f_nn |
| 56 | fprop | Enc_1:Attn:SelfAttention | contiguous | T=(4,128,16,64), | legacy::elementwise_kernel |
| 57 | fprop | Enc_1:Attn:Output | linear | M=1024,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_tn |
| 58 | fprop | Enc_1:Attn:Output | bias | M=1024,N=(4,128), | legacy::elementwise_kernel |
| 59 | fprop | Enc_1:Attn:Output | dropout | [4,128,1024] | fused_dropout_kernel |
| 60 | fprop | Enc_1:Attn:Output | __add__ | [4,128,1024];[4,128,1024] | modern::elementwise_kernel |
| 61 | fprop | Enc_1:Attn:Output:LayerNorm | forward_affine | T=[(4,128,1024),(1024,),(1024,)], | cuApplyLayerNorm |
| 62 | fprop | Enc_1:FFN | linear | M=4096,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x256_ldg8_f2f_tn |
| 63 | fprop | Enc_1:FFN | FusionGroup | na | kernel_0 |
| 64 | fprop | Enc_1:FFN | linear | M=1024,N=(4,128),K=4096, | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_tn |
| 65 | fprop | Enc_1:FFN | bias | M=1024,N=(4,128), | legacy::elementwise_kernel |
| 66 | fprop | Enc_1:FFN | dropout | [4,128,1024] | fused_dropout_kernel |
| 67 | fprop | Enc_1:FFN | __add__ | [4,128,1024];[4,128,1024] | modern::elementwise_kernel |
| 68 | fprop | Enc_1:FFN:LayerNorm | forward_affine | T=[(4,128,1024),(1024,),(1024,)], | cuApplyLayerNorm |
BERT pre-training has two unsupervised tasks.
- Masked language modeling (Masked LM).
- Next sentence prediction (NSP).
NSP
The hidden state corresponding to the first token (CLS) is fed to a
Linear layer with Tanh activation. The output has the same shape as the
input. Kernels 69 through 72 correspond to this operation. The output
is fed to another Linear layer. The resulting output has the shape
[batch_size, 2]. Kernels 78-80 correspond to this operation.
Masked LM
The entire output of the last encoder ([batch_size, sequence_length, hidden_size]) is fed to a Linear layer with GELU activation followed by
Layer Norm. The output has the same shape as the input. Kernels 73-75
correspond to this operation. The output is fed to another Linear
layer such that the final shape is [batch_size, sequence_length, vocab_size]. Kernels 76 and 77 correspond to this operation.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 69 | fprop | NSP | linear | M=1024,N=4,K=1024, | turing_fp16_s1688gemm_fp16_256x64_ldg8_f2f_tn |
| 70 | fprop | NSP | linear | M=1024,N=4,K=1024, | splitKreduce_kernel |
| 71 | fprop | NSP | __add__ | [1024];[4,1024] | legacy::elementwise_kernel |
| 72 | fprop | NSP | tanh | [4,1024] | kernelPointwiseApply2 |
| 73 | fprop | Masked_LM | linear | M=1024,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_tn |
| 74 | fprop | Masked_LM | FusionGroup | na | kernel_0 |
| 75 | fprop | Masked_LM:LayerNorm | forward_affine | T=[(4,128,1024),(1024,),(1024,)], | cuApplyLayerNorm |
| 76 | fprop | Masked_LM | linear | M=30528,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_256x128_ldg8_f2f_tn |
| 77 | fprop | Masked_LM | __add__ | [4,128,30528];[30528] | legacy::elementwise_kernel |
| 78 | fprop | NSP | bias | M=2,N=4, | legacy::elementwise_kernel |
| 79 | fprop | NSP | linear | M=2,N=4,K=1024, | volta_fp16_sgemm_fp16_32x32_sliced1x4_tn |
| 80 | fprop | NSP | linear | M=2,N=4,K=1024, | splitKreduce_kernel |
Loss
The total loss is the sum of the Masked LM loss and NSP loss. Kernels 81 through 87 correspond to the loss calculations and loss scaling.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 81 | fprop | Masked_LM_Loss | cross_entropy | T=[(512,30528),(512,)],[] | cunn_SoftMaxForward |
| 82 | fprop | Masked_LM_Loss | cross_entropy | T=[(512,30528),(512,)],[] | cunn_ClassNLLCriterion_updateOutput_kernel |
| 83 | fprop | Next_Sent_Loss | cross_entropy | T=[(4,2),(4,)],[] | softmax_warp_forward |
| 84 | fprop | Next_Sent_Loss | cross_entropy | T=[(4,2),(4,)],[] | cunn_ClassNLLCriterion_updateOutput_kernel |
| 85 | fprop | Total_Loss | __add__ | [];[] | legacy::elementwise_kernel |
| 86 | fprop | - | float | [] | legacy::elementwise_kernel |
| 87 | fprop | - | __mul__ | [];[] | legacy::elementwise_kernel |
Loss (bprop)
Kernels 89 through 94 correspond to the back prop through the loss layers.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 88 | fprop | - | backward | legacy::elementwise_kernel | |
| 89 | bprop | - | __mul__ | [];[] | legacy::elementwise_kernel |
| 90 | fprop | - | to | na | legacy::elementwise_kernel |
| 91 | bprop | Next_Sent_Loss | cross_entropy | T=[(4,2),(4,)],[] | cunn_ClassNLLCriterion_updateGradInput_kernel |
| 92 | bprop | Next_Sent_Loss | cross_entropy | T=[(4,2),(4,)],[] | softmax_warp_backward |
| 93 | bprop | Masked_LM_Loss | cross_entropy | T=[(512,30528),(512,)],[] | cunn_ClassNLLCriterion_updateGradInput_kernel |
| 94 | bprop | Masked_LM_Loss | cross_entropy | T=[(512,30528),(512,)],[] | cunn_SoftMaxBackward |
NSP and Masked LM (bprop)
Kernels 95-97 and 108-112 correspond to the back prop (weight gradient and data gradient) through the NSP calculations. Kernels 97 and 109 correspond to the bias gradient. Kernels 98-107 correspond to the back prop through the Masked LM calculations. Kernel 98 is for bias gradient. Kernels 101-103 correspond to Layer Norm. Kernels 104 and 105 correspond to the fused GELU activation.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 95 | bprop | NSP | linear | M=1024,N=4,K=2, | gemmSN_NN_kernel |
| 96 | bprop | NSP | linear | M=1024,N=2,K=4, | volta_fp16_sgemm_fp16_32x128_nt |
| 97 | fprop | - | sum | na | reduce_kernel |
| 98 | fprop | - | sum | na | reduce_kernel |
| 99 | bprop | Masked_LM | linear | M=1024,N=(4,128),K=30528, | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_nt |
| 100 | bprop | Masked_LM | linear | M=1024,N=30528,K=(4,128), | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_nn |
| 101 | bprop | - | backward_affine | T=[(4,128,1024),(512,),(512,),(4,128,1024),(1024,),(1024,)], | cuComputePartGradGammaBeta |
| 102 | bprop | - | backward_affine | T=[(4,128,1024),(512,),(512,),(4,128,1024),(1024,),(1024,)], | cuComputeGradGammaBeta |
| 103 | bprop | - | backward_affine | T=[(4,128,1024),(512,),(512,),(4,128,1024),(1024,),(1024,)], | cuComputeGradInput |
| 104 | bprop | - | DifferentiableGraph | na | kernel_1 |
| 105 | bprop | - | DifferentiableGraph | na | reduce_kernel |
| 106 | bprop | Masked_LM | linear | M=1024,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x256_ldg8_f2f_nt |
| 107 | bprop | Masked_LM | linear | M=1024,N=1024,K=(4,128), | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_nn |
| 108 | bprop | NSP | tanh | [4,1024] | modern::elementwise_kernel |
| 109 | fprop | - | sum | na | reduce_kernel |
| 110 | bprop | NSP | linear | M=1024,N=4,K=1024, | volta_fp16_sgemm_fp16_128x64_nt |
| 111 | bprop | NSP | linear | M=1024,N=1024,K=4, | turing_s884gemm_fp16_128x64_ldg8_nn |
| 112 | bprop | NSP | linear | X=(4,1024),W=(1024,1024), | splitKreduce_kernel |
| 113 | bprop | - | Select | na | modern::elementwise_kernel |
| 114 | bprop | - | Select | na | legacy::elementwise_kernel |
| 115 | bprop | - | Slice | na | modern::elementwise_kernel |
| 116 | fprop | - | add | na | modern::elementwise_kernel |
Encoder 1: FFN (bprop)
Kernels 117-119 correspond to Layer Norm. Kernel 121 calculates the bias gradient. Kernels 122 and 123 calculate the data gradient and weight gradient of the second Linear layer. Kernels 124 and 125 correspond to the fused GELU activation. Kernels 126 and 127 calculate the data gradient and weight gradient of the first Linear layer. Kernel 128 adds the gradients due to the residual connection.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 117 | bprop | - | backward_affine | T=[(4,128,1024),(512,),(512,),(4,128,1024),(1024,),(1024,)], | cuComputePartGradGammaBeta |
| 118 | bprop | - | backward_affine | T=[(4,128,1024),(512,),(512,),(4,128,1024),(1024,),(1024,)], | cuComputeGradGammaBeta |
| 119 | bprop | - | backward_affine | T=[(4,128,1024),(512,),(512,),(4,128,1024),(1024,),(1024,)], | cuComputeGradInput |
| 120 | bprop | Enc_1:FFN | dropout | [4,128,1024] | kernelPointwiseApply3 |
| 121 | fprop | - | sum | na | reduce_kernel |
| 122 | bprop | Enc_1:FFN | linear | M=4096,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_nt |
| 123 | bprop | Enc_1:FFN | linear | M=4096,N=1024,K=(4,128), | turing_fp16_s1688gemm_fp16_128x256_ldg8_f2f_nn |
| 124 | bprop | - | DifferentiableGraph | na | kernel_1 |
| 125 | bprop | - | DifferentiableGraph | na | reduce_kernel |
| 126 | bprop | Enc_1:FFN | linear | M=1024,N=(4,128),K=4096, | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_nt |
| 127 | bprop | Enc_1:FFN | linear | M=1024,N=4096,K=(4,128), | turing_fp16_s1688gemm_fp16_128x256_ldg8_f2f_nn |
| 128 | fprop | - | add | na | modern::elementwise_kernel |
Encoder 1: Multi-Head Attention (bprop)
Kernels 129-131 correspond to Layer Norm. Kernel 133 calculates the bias gradient. Kernels 134 and 135 calculate the data gradient and weight gradient through the output Linear layers. Kernels 137 and 138 calculate two data gradients, one for each input of the batched matrix multiply. Likewise, kernels 143 and 144 calculate two data gradients. Kernels 147, 148 and 149 correspond to bias, data and weight gradient through the projection of $V$. Likewise, kernels 151, 153 and 154 correspond to the projection of $K$ and kernels 156-158 correspond to the projection of $Q$. Kernels 150, 155 and 159 most likely correspond to the summation of the data gradients from $V$, $K$ and $Q$ projections.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 129 | bprop | - | backward_affine | T=[(4,128,1024),(512,),(512,),(4,128,1024),(1024,),(1024,)], | cuComputePartGradGammaBeta |
| 130 | bprop | - | backward_affine | T=[(4,128,1024),(512,),(512,),(4,128,1024),(1024,),(1024,)], | cuComputeGradGammaBeta |
| 131 | bprop | - | backward_affine | T=[(4,128,1024),(512,),(512,),(4,128,1024),(1024,),(1024,)], | cuComputeGradInput |
| 132 | bprop | Enc_1:Attn:Output | dropout | [4,128,1024] | kernelPointwiseApply3 |
| 133 | fprop | - | sum | na | reduce_kernel |
| 134 | bprop | Enc_1:Attn:Output | linear | M=1024,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x256_ldg8_f2f_nt |
| 135 | bprop | Enc_1:Attn:Output | linear | M=1024,N=1024,K=(4,128), | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_nn |
| 136 | bprop | - | UnsafeView | na | legacy::elementwise_kernel |
| 137 | bprop | Enc_1:Attn:SelfAttn:QKV | matmul | A=(4,16,128,128),B=(4,16,128,64), | turing_fp16_s884gemm_fp16_64x64_ldg8_f2f_nt |
| 138 | bprop | Enc_1:Attn:SelfAttn:QKV | matmul | A=(4,16,128,128),B=(4,16,128,64), | turing_fp16_s884gemm_fp16_64x64_ldg8_f2f_tn |
| 139 | bprop | Enc_1:Attn:SelfAttn:Dropout | dropout | [4,16,128,128] | kernelPointwiseApply3 |
| 140 | bprop | Enc_1:Attn:SelfAttn:SoftMax | softmax | [4,16,128,128] | modern::elementwise_kernel |
| 141 | bprop | Enc_1:Attn:SelfAttn:SoftMax | softmax | [4,16,128,128] | softmax_warp_backward |
| 142 | bprop | Enc_1:Attn:SelfAttn:Scale | __truediv__ | [4,16,128,128];[] | modern::elementwise_kernel |
| 143 | bprop | Enc_1:Attn:SelfAttn:Q.K | matmul | A=(4,16,128,64),B=(4,16,64,128), | turing_fp16_s884gemm_fp16_64x64_ldg8_f2f_nt |
| 144 | bprop | Enc_1:Attn:SelfAttn:Q.K | matmul | A=(4,16,128,64),B=(4,16,64,128), | turing_fp16_s884gemm_fp16_64x64_ldg8_f2f_tn |
| 145 | bprop | - | View | na | legacy::elementwise_kernel |
| 146 | bprop | - | View | na | legacy::elementwise_kernel |
| 147 | fprop | - | sum | na | reduce_kernel |
| 148 | bprop | Enc_1:Attn:SelfAttn:V_Proj | linear | M=1024,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x256_ldg8_f2f_nt |
| 149 | bprop | Enc_1:Attn:SelfAttn:V_Proj | linear | M=1024,N=1024,K=(4,128), | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_nn |
| 150 | fprop | - | add | na | modern::elementwise_kernel |
| 151 | fprop | - | sum | na | reduce_kernel |
| 152 | bprop | - | UnsafeView | na | legacy::elementwise_kernel |
| 153 | bprop | Enc_1:Attn:SelfAttn:K_Proj | linear | M=1024,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x256_ldg8_f2f_nt |
| 154 | bprop | Enc_1:Attn:SelfAttn:K_Proj | linear | M=1024,N=1024,K=(4,128), | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_nn |
| 155 | fprop | - | add | na | modern::elementwise_kernel |
| 156 | fprop | - | sum | na | reduce_kernel |
| 157 | bprop | Enc_1:Attn:SelfAttn:Q_Proj | linear | M=1024,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x256_ldg8_f2f_nt |
| 158 | bprop | Enc_1:Attn:SelfAttn:Q_Proj | linear | M=1024,N=1024,K=(4,128), | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_nn |
| 159 | fprop | - | add | na | modern::elementwise_kernel |
Encoder 0 (bprop)
Kernels 160 through 202 correspond to the first encoder block. They are exactly the same as the second encoder block.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 160 | bprop | - | backward_affine | T=[(4,128,1024),(512,),(512,),(4,128,1024),(1024,),(1024,)], | cuComputePartGradGammaBeta |
| 161 | bprop | - | backward_affine | T=[(4,128,1024),(512,),(512,),(4,128,1024),(1024,),(1024,)], | cuComputeGradGammaBeta |
| 162 | bprop | - | backward_affine | T=[(4,128,1024),(512,),(512,),(4,128,1024),(1024,),(1024,)], | cuComputeGradInput |
| 163 | bprop | Enc_0:FFN | dropout | [4,128,1024] | kernelPointwiseApply3 |
| 164 | fprop | - | sum | na | reduce_kernel |
| 165 | bprop | Enc_0:FFN | linear | M=4096,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_nt |
| 166 | bprop | Enc_0:FFN | linear | M=4096,N=1024,K=(4,128), | turing_fp16_s1688gemm_fp16_128x256_ldg8_f2f_nn |
| 167 | bprop | - | DifferentiableGraph | na | kernel_1 |
| 168 | bprop | - | DifferentiableGraph | na | reduce_kernel |
| 169 | bprop | Enc_0:FFN | linear | M=1024,N=(4,128),K=4096, | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_nt |
| 170 | bprop | Enc_0:FFN | linear | M=1024,N=4096,K=(4,128), | turing_fp16_s1688gemm_fp16_128x256_ldg8_f2f_nn |
| 171 | fprop | - | add | na | modern::elementwise_kernel |
| 172 | bprop | - | backward_affine | T=[(4,128,1024),(512,),(512,),(4,128,1024),(1024,),(1024,)], | cuComputePartGradGammaBeta |
| 173 | bprop | - | backward_affine | T=[(4,128,1024),(512,),(512,),(4,128,1024),(1024,),(1024,)], | cuComputeGradGammaBeta |
| 174 | bprop | - | backward_affine | T=[(4,128,1024),(512,),(512,),(4,128,1024),(1024,),(1024,)], | cuComputeGradInput |
| 175 | bprop | Enc_0:Attn:Output | dropout | [4,128,1024] | kernelPointwiseApply3 |
| 176 | fprop | - | sum | na | reduce_kernel |
| 177 | bprop | Enc_0:Attn:Output | linear | M=1024,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x256_ldg8_f2f_nt |
| 178 | bprop | Enc_0:Attn:Output | linear | M=1024,N=1024,K=(4,128), | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_nn |
| 179 | bprop | - | UnsafeView | na | legacy::elementwise_kernel |
| 180 | bprop | Enc_0:Attn:SelfAttn:QKV | matmul | A=(4,16,128,128),B=(4,16,128,64), | turing_fp16_s884gemm_fp16_64x64_ldg8_f2f_nt |
| 181 | bprop | Enc_0:Attn:SelfAttn:QKV | matmul | A=(4,16,128,128),B=(4,16,128,64), | turing_fp16_s884gemm_fp16_64x64_ldg8_f2f_tn |
| 182 | bprop | Enc_0:Attn:SelfAttn:Dropout | dropout | [4,16,128,128] | kernelPointwiseApply3 |
| 183 | bprop | Enc_0:Attn:SelfAttn:SoftMax | softmax | [4,16,128,128] | modern::elementwise_kernel |
| 184 | bprop | Enc_0:Attn:SelfAttn:SoftMax | softmax | [4,16,128,128] | softmax_warp_backward |
| 185 | bprop | Enc_0:Attn:SelfAttn:Scale | __truediv__ | [4,16,128,128];[] | modern::elementwise_kernel |
| 186 | bprop | Enc_0:Attn:SelfAttn:Q.K | matmul | A=(4,16,128,64),B=(4,16,64,128), | turing_fp16_s884gemm_fp16_64x64_ldg8_f2f_nt |
| 187 | bprop | Enc_0:Attn:SelfAttn:Q.K | matmul | A=(4,16,128,64),B=(4,16,64,128), | turing_fp16_s884gemm_fp16_64x64_ldg8_f2f_tn |
| 188 | bprop | - | View | na | legacy::elementwise_kernel |
| 189 | bprop | - | View | na | legacy::elementwise_kernel |
| 190 | fprop | - | sum | na | reduce_kernel |
| 191 | bprop | Enc_0:Attn:SelfAttn:V_Proj | linear | M=1024,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x256_ldg8_f2f_nt |
| 192 | bprop | Enc_0:Attn:SelfAttn:V_Proj | linear | M=1024,N=1024,K=(4,128), | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_nn |
| 193 | fprop | - | add | na | modern::elementwise_kernel |
| 194 | fprop | - | sum | na | reduce_kernel |
| 195 | bprop | - | UnsafeView | na | legacy::elementwise_kernel |
| 196 | bprop | Enc_0:Attn:SelfAttn:K_Proj | linear | M=1024,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x256_ldg8_f2f_nt |
| 197 | bprop | Enc_0:Attn:SelfAttn:K_Proj | linear | M=1024,N=1024,K=(4,128), | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_nn |
| 198 | fprop | - | add | na | modern::elementwise_kernel |
| 199 | fprop | - | sum | na | reduce_kernel |
| 200 | bprop | Enc_0:Attn:SelfAttn:Q_Proj | linear | M=1024,N=(4,128),K=1024, | turing_fp16_s1688gemm_fp16_128x256_ldg8_f2f_nt |
| 201 | bprop | Enc_0:Attn:SelfAttn:Q_Proj | linear | M=1024,N=1024,K=(4,128), | turing_fp16_s1688gemm_fp16_128x128_ldg8_f2f_nn |
| 202 | fprop | - | add | na | modern::elementwise_kernel |
Embedding (bprop)
Kernels 204-206 correspond to Layer Norm.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 203 | bprop | Embedding | dropout | [4,128,1024] | kernelPointwiseApply3 |
| 204 | bprop | - | backward_affine | T=[(4,128,1024),(512,),(512,),(4,128,1024),(1024,),(1024,)], | cuComputePartGradGammaBeta |
| 205 | bprop | - | backward_affine | T=[(4,128,1024),(512,),(512,),(4,128,1024),(1024,),(1024,)], | cuComputeGradGammaBeta |
| 206 | bprop | - | backward_affine | T=[(4,128,1024),(512,),(512,),(4,128,1024),(1024,),(1024,)], | cuComputeGradInput |
| 207 | bprop | Embedding:Segment | embedding | [4,128];[2,1024] | modern::elementwise_kernel |
| 208 | bprop | Embedding:Segment | embedding | [4,128];[2,1024] | embedding_backward_feature_kernel |
| 209 | bprop | Embedding:Position | embedding | [4,128];[512,1024] | legacy::elementwise_kernel |
| 210 | bprop | Embedding:Position | embedding | [4,128];[512,1024] | modern::elementwise_kernel |
| 211 | bprop | Embedding:Position | embedding | [4,128];[512,1024] | embedding_backward_feature_kernel |
| 212 | bprop | Embedding:Token | embedding | [4,128];[30528,1024] | modern::elementwise_kernel |
| 213 | bprop | Embedding:Token | embedding | [4,128];[30528,1024] | embedding_backward_feature_kernel |
Optimizer
Kernels 214 through 265 correspond to the LAMB optimizer.
| Idx | Direction | Layer | Op | Params | Kernel |
|---|---|---|---|---|---|
| 214 | fprop | - | add | na | modern::elementwise_kernel |
| 215 | fprop | - | zero_ | [1] | modern::elementwise_kernel |
| 216 | fprop | - | na | multi_tensor_apply_kernel | |
| 217 | fprop | - | na | multi_tensor_apply_kernel | |
| 218 | fprop | - | na | multi_tensor_apply_kernel | |
| 219 | fprop | - | zero_ | [1] | modern::elementwise_kernel |
| 220 | fprop | - | multi_tensor_scale | T=[(1,),(30528,1024),(512,1024),(2,1024),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(2,1024),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(30528,),(1024,),(1024,),(1024,),(2,),(30528,1024),(512,1024),(2,1024),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(2,1024),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(30528,),(1024,),(1024,),(1024,),(2,)] | multi_tensor_apply_kernel |
| 221 | fprop | - | multi_tensor_scale | T=[(1,),(30528,1024),(512,1024),(2,1024),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(2,1024),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(30528,),(1024,),(1024,),(1024,),(2,),(30528,1024),(512,1024),(2,1024),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(2,1024),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(30528,),(1024,),(1024,),(1024,),(2,)], | multi_tensor_apply_kernel |
| 222 | fprop | - | multi_tensor_scale | T=[(1,),(30528,1024),(512,1024),(2,1024),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(2,1024),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(30528,),(1024,),(1024,),(1024,),(2,),(30528,1024),(512,1024),(2,1024),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(2,1024),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(30528,),(1024,),(1024,),(1024,),(2,)], | multi_tensor_apply_kernel |
| 223 | fprop | - | zero_ | [1] | modern::elementwise_kernel |
| 224 | fprop | - | multi_tensor_scale | T=[(1,),(30528,1024),(512,1024),(2,1024),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(2,1024),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(30528,),(1024,),(1024,),(1024,),(2,),(30528,1024),(512,1024),(2,1024),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(2,1024),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(30528,),(1024,),(1024,),(1024,),(2,)], | multi_tensor_apply_kernel |
| 225 | fprop | - | multi_tensor_scale | T=[(1,),(30528,1024),(512,1024),(2,1024),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(2,1024),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(30528,),(1024,),(1024,),(1024,),(2,),(30528,1024),(512,1024),(2,1024),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(2,1024),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(30528,),(1024,),(1024,),(1024,),(2,)], | multi_tensor_apply_kernel |
| 226 | fprop | - | multi_tensor_scale | T=[(1,),(30528,1024),(512,1024),(2,1024),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(2,1024),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(30528,),(1024,),(1024,),(1024,),(2,),(30528,1024),(512,1024),(2,1024),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(1024,1024),(1024,1024),(4096,1024),(1024,4096),(1024,1024),(1024,1024),(2,1024),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(1024,),(4096,),(1024,),(1024,),(1024,),(1024,),(30528,),(1024,),(1024,),(1024,),(2,)], | multi_tensor_apply_kernel |
| 227 | fprop | - | zero_ | na | modern::elementwise_kernel |
| 228 | fprop | - | na | multi_tensor_apply_kernel | |
| 229 | fprop | - | na | multi_tensor_apply_kernel | |
| 230 | fprop | - | na | multi_tensor_apply_kernel | |
| 231 | fprop | - | na | cleanup | |
| 232 | fprop | - | zero_ | na | modern::elementwise_kernel |
| 233 | fprop | - | zero_ | na | modern::elementwise_kernel |
| 234 | fprop | - | na | multi_tensor_apply_kernel | |
| 235 | fprop | - | na | multi_tensor_apply_kernel | |
| 236 | fprop | - | na | multi_tensor_apply_kernel | |
| 237 | fprop | - | na | cleanup | |
| 238 | fprop | - | na | multi_tensor_apply_kernel | |
| 239 | fprop | - | na | multi_tensor_apply_kernel | |
| 240 | fprop | - | na | multi_tensor_apply_kernel | |
| 241 | fprop | - | zero_ | na | modern::elementwise_kernel |
| 242 | fprop | - | zero_ | na | modern::elementwise_kernel |
| 243 | fprop | - | na | multi_tensor_apply_kernel | |
| 244 | fprop | - | na | multi_tensor_apply_kernel | |
| 245 | fprop | - | na | multi_tensor_apply_kernel | |
| 246 | fprop | - | na | cleanup | |
| 247 | fprop | - | na | multi_tensor_apply_kernel | |
| 248 | fprop | - | na | multi_tensor_apply_kernel | |
| 249 | fprop | - | na | multi_tensor_apply_kernel | |
| 250 | fprop | - | zero_ | na | modern::elementwise_kernel |
| 251 | fprop | - | na | multi_tensor_apply_kernel | |
| 252 | fprop | - | na | cleanup | |
| 253 | fprop | - | zero_ | na | modern::elementwise_kernel |
| 254 | fprop | - | zero_ | na | modern::elementwise_kernel |
| 255 | fprop | - | na | multi_tensor_apply_kernel | |
| 256 | fprop | - | na | cleanup | |
| 257 | fprop | - | na | multi_tensor_apply_kernel | |
| 258 | fprop | - | zero_ | na | modern::elementwise_kernel |
| 259 | fprop | - | zero_ | na | modern::elementwise_kernel |
| 260 | fprop | - | na | multi_tensor_apply_kernel | |
| 261 | fprop | - | na | cleanup | |
| 262 | fprop | - | na | multi_tensor_apply_kernel | |
| 263 | fprop | - | na | multi_tensor_apply_kernel | |
| 264 | fprop | - | na | multi_tensor_apply_kernel | |
| 265 | fprop | - | na | multi_tensor_apply_kernel |